
Mesin penerjemahan
Apa itu mesin penerjemahan?
Sistem penerjemahan mesin adalah aplikasi atau layanan online yang menggunakan teknologi pembelajaran mesin untuk menerjemahkan sejumlah besar teks dari dan ke bahasa yang didukung. Layanan menerjemahkan teks "sumber" dari satu bahasa ke bahasa yang berbeda "target".
Meskipun konsep di balik teknologi penerjemahan mesin dan antarmuka untuk menggunakannya relatif sederhana, ilmu pengetahuan dan teknologi di belakangnya sangat kompleks dan menyatukan beberapa teknologi terdepan, khususnya, pembelajaran mendalam ( kecerdasan buatan), data besar, linguistik, komputasi awan, dan api web.
Sejak awal 2010-an, teknologi kecerdasan buatan yang baru, Jaringan neural yang dalam (alias pembelajaran yang mendalam), telah memungkinkan teknologi pengenalan ucapan mencapai tingkat kualitas yang memungkinkan tim penerjemah Microsoft menggabungkan pengenalan ucapan dengan teknologi penerjemahan teks inti untuk meluncurkan teknologi terjemahan ucapan baru.
Secara historis, teknik pembelajaran mesin utama yang digunakan dalam industri adalah Statistik mesin terjemahan (SMT). SMT menggunakan analisis statistik canggih untuk memperkirakan terjemahan terbaik untuk sebuah kata yang diberikan konteks beberapa kata. SMT telah digunakan sejak pertengahan tahun 2000-an oleh semua penyedia layanan penerjemahan utama, termasuk Microsoft.
Munculnya mesin Neural Translation (NMT) menyebabkan pergeseran radikal dalam teknologi penerjemahan, menghasilkan terjemahan yang jauh lebih berkualitas. Teknologi penerjemahan ini mulai menggelar untuk pengguna dan pengembang di bagian akhir dari 2016.
Kedua teknologi terjemahan SMT dan NMT memiliki dua unsur kesamaan:
- Keduanya membutuhkan sejumlah besar konten diterjemahkan pra-manusia (sampai jutaan kalimat diterjemahkan) untuk melatih sistem.
- Tidak bertindak sebagai Kamus dwibahasa, menerjemahkan kata berdasarkan daftar terjemahan potensial, tetapi menerjemahkan berdasarkan konteks kata yang digunakan dalam kalimat.
Apa itu Translator?
Layanan penerjemah dan ucapan, Bagian dari Layanan kognitif Koleksi api, adalah layanan terjemahan mesin dari Microsoft.
Terjemahan teks
Penerjemah telah digunakan oleh grup Microsoft sejak 2007 dan tersedia sebagai API untuk pelanggan sejak 2011. Penerjemah digunakan secara luas dalam Microsoft. Hal ini dimasukkan di seluruh lokalisasi produk, dukungan, dan tim komunikasi online. Layanan yang sama ini juga dapat diakses, tanpa biaya tambahan, dari dalam produk Microsoft yang sudah dikenal seperti Bing, Cortana, Microsoft ujung, Kantor, Sharepoint, Skypedan Heboh.
Penerjemah dapat digunakan dalam aplikasi web atau klien pada setiap platform hardware dan dengan sistem operasi untuk melakukan terjemahan bahasa dan operasi lain yang terkait bahasa seperti deteksi bahasa, teks ke ucapan, atau Kamus.
Memanfaatkan teknologi REST standar industri, pengembang mengirimkan teks sumber (atau audio untuk terjemahan ucapan) ke layanan dengan parameter yang menunjukkan bahasa target, dan layanan mengirimkan kembali teks terjemahan untuk aplikasi klien atau web untuk digunakan.
Layanan penerjemah adalah layanan Azure host di pusat data Microsoft dan manfaat dari keamanan, skalabilitas, keandalan, dan ketersediaan nonstop yang juga menerima layanan awan Microsoft lainnya.
Pidato terjemahan
Teknologi penerjemah terjemahan ucapan diluncurkan akhir 2014 dimulai dengan Skype Translator, dan tersedia sebagai API terbuka untuk pelanggan sejak awal 2016. Ini diintegrasikan ke dalam fitur langsung Penerjemah Microsoft, Skype, siaran rapat Skype, dan aplikasi Penerjemah Microsoft untuk Android dan iOS.
Ucapan terjemahan sekarang tersedia melalui Microsoft Speech, set end-to-end sepenuhnya disesuaikan layanan untuk pengenalan ucapan, pidato terjemahan, dan pidato sintesis (Text-to-Speech).
Bagaimana cara kerja penerjemahan teks?
Ada dua teknologi utama yang digunakan untuk penerjemahan teks: yang lama, terjemahan mesin Statistik (SMT), dan satu generasi yang lebih baru, Mesin Neural Translation (NMT).
Mesin Statistik terjemahan
Implementasi penerjemah pada statistik mesin terjemahan (SMT) dibangun pada lebih dari satu dekade penelitian bahasa alami di Microsoft. Daripada menulis aturan buatan tangan untuk menerjemahkan antara bahasa, sistem terjemahan modern pendekatan terjemahan sebagai masalah belajar transformasi teks antara bahasa dari terjemahan manusia yang ada dan memanfaatkan kemajuan terbaru dalam statistik Terapan dan pembelajaran mesin.
Disebut "corpora paralel" bertindak sebagai batu Rosetta modern dalam proporsi besar, menyediakan kata, frase, dan terjemahan idiomatik dalam konteks banyak pasangan bahasa dan domain. Teknik pemodelan Statistik dan algoritma yang efisien membantu alamat komputer masalah penguraian (mendeteksi korespondensi antara sumber dan bahasa target dalam data pelatihan) dan decoding (menemukan terjemahan terbaik dari kalimat input baru). Penerjemah menyatukan kekuatan metode statistik dengan informasi linguistik untuk menghasilkan model yang menggeneralisasikan lebih baik dan mengarah ke terjemahan lebih dipahami.
Karena pendekatan ini, yang tidak bergantung pada kamus atau aturan gramatikal, ia menyediakan terjemahan frase terbaik di mana ia dapat menggunakan konteks di sekitar kata tertentu versus mencoba untuk melakukan terjemahan kata tunggal. Untuk terjemahan kata tunggal, Kamus dwibahasa dikembangkan dan dapat diakses melalui www.Bing.com/Translator.
Mesin saraf terjemahan
Perbaikan terus-menerus untuk terjemahan penting. Namun, peningkatan kinerja telah stabil dengan teknologi SMT sejak pertengahan 2010-an. Dengan memanfaatkan skala dan kekuatan dari Supercomputer AI Microsoft, khususnya Microsoft Cognitive toolkit, Translator sekarang menawarkan jaringan syaraf tiruan (LSTM DI) berdasarkan terjemahan yang memungkinkan dekade baru peningkatan kualitas terjemahan.
Model jaringan Neural ini tersedia untuk semua bahasa ucapan melalui Layanan ucapan di Azure dan melalui API teks dengan menggunakan ' generalnn ' Kategori ID.
Terjemahan jaringan Neural secara fundamental berbeda dalam bagaimana mereka dilakukan dibandingkan dengan yang SMT tradisional.
Animasi berikut ini menggambarkan berbagai langkah terjemahan jaringan saraf pergi melalui menerjemahkan kalimat. Karena pendekatan ini, terjemahan akan mengambil ke dalam konteks kalimat penuh, versus hanya beberapa kata geser jendela yang menggunakan teknologi SMT dan akan menghasilkan lebih cair dan diterjemahkan manusia terjemahan mencari.
Berdasarkan pelatihan jaringan Neural, setiap kata dikodekan sepanjang vektor 500 dimensi (a) mewakili karakteristik unik dalam pasangan bahasa tertentu (misalnya Inggris dan Cina). Berdasarkan pasangan bahasa yang digunakan untuk pelatihan, jaringan saraf akan menentukan sendiri apa yang harus dimensi ini. Mereka bisa mengkodekan konsep sederhana seperti jenis kelamin (feminin, maskulin, netral), tingkat kesopanan (slang, kasual, tertulis, formal, dll), jenis kata (kata kerja, kata benda, dll), tetapi juga karakteristik non-jelas lainnya sebagai berasal dari data pelatihan.
Langkah terjemahan jaringan saraf melalui adalah sebagai berikut:
- Setiap kata, atau lebih khusus vektor 500-dimensi yang mewakili itu, berjalan melalui lapisan pertama "neuron" yang akan mengkodekan dalam vektor 1000-dimensi (b) mewakili kata dalam konteks kata lain dalam kalimat.
- Setelah semua kata telah dikodekan satu kali ke dalam 1000-dimensi ini vektor, proses diulang beberapa kali, setiap lapisan yang lebih baik memungkinkan fine-tuning ini 1000-dimensi representasi dari kata dalam konteks kalimat penuh (bertentangan dengan SMT teknologi yang hanya dapat mempertimbangkan 3 sampai 5 kata jendela)
- Matriks Keluaran terakhir kemudian digunakan oleh lapisan perhatian (yaitu algoritma perangkat lunak) yang akan menggunakan kedua matriks keluaran akhir ini dan output dari kata-kata yang diterjemahkan sebelumnya untuk menentukan kata mana, dari kalimat sumber, harus diterjemahkan berikutnya. Ini juga akan menggunakan perhitungan ini berpotensi drop kata yang tidak perlu dalam bahasa target.
- The decoder (terjemahan) lapisan, menerjemahkan kata yang dipilih (atau lebih khusus vektor 1000-dimensi yang mewakili kata ini dalam konteks penuh kalimat) dalam bahasa target yang paling sesuai setara. Output dari lapisan terakhir ini (c) kemudian diberi makan kembali ke lapisan perhatian untuk menghitung kata berikutnya dari kalimat sumber harus diterjemahkan.

Dalam contoh yang digambarkan dalam animasi, model sadar-1000-dimensi konteks "Tje"akan menyandikan bahwa kata benda (Rumah) adalah kata feminin dalam bahasa Prancis (La Maison). Ini akan memungkinkan terjemahan yang sesuai untuk "Tje"menjadi"La"dan tidak"Le"(tunggal, pria) atau"Les"(jamak) setelah mencapai decoder (terjemahan) lapisan.
Algoritma perhatian juga akan menghitung, berdasarkan kata (s) sebelumnya diterjemahkan (dalam hal ini "Tje"), bahwa kata berikutnya yang akan diterjemahkan harus subjek ("Rumah") dan bukan Adjektiva ("Biru"). Dalam dapat mencapai hal ini karena sistem belajar bahwa bahasa Inggris dan Perancis balikkan urutan kata ini dalam kalimat. Itu juga akan menghitung bahwa jika kata sifat menjadi "Besar"bukan warna, bahwa itu tidak boleh balikkan mereka ("rumah besar"= >"La Grande Maison").
Berkat pendekatan ini, output akhir adalah, dalam banyak kasus, lebih fasih dan lebih dekat dengan terjemahan manusia daripada terjemahan berbasis SMT bisa pernah.
Bagaimana cara kerja penerjemahan ucapan?
Translator juga mampu menerjemahkan pidato. Teknologi ini terbuka dalam fitur live Translator (http://translate.it), aplikasi penerjemah, Skype Translator dan juga awalnya disediakan hanya melalui fitur penerjemah Skype dan di aplikasi Microsoft Translator di iOS dan Android, fungsi ini sekarang tersedia untuk pengembang dengan versi terbaru dari Open API berbasis REST tersedia di Azure portal.
Meskipun mungkin tampak seperti proses lurus ke depan pada pandangan pertama untuk membangun teknologi terjemahan ucapan dari batu bata teknologi yang ada, diperlukan lebih banyak pekerjaan daripada hanya memasukkan yang ada "tradisional" manusia-untuk-mesin pengenalan pidato mesin ke terjemahan teks yang ada.
Untuk benar menerjemahkan "sumber" pidato dari satu bahasa yang berbeda "target" bahasa, sistem berjalan melalui proses empat langkah.
- Pengenalan ucapan, untuk mengkonversi audio ke dalam teks
- TrueText: sebuah teknologi Microsoft yang menormalkan teks untuk membuatnya lebih tepat untuk terjemahan
- Terjemahan melalui mesin penerjemahan teks yang dijelaskan di atas tetapi pada model terjemahan khusus dikembangkan untuk percakapan berbicara kehidupan nyata
- Text-to-Speech, bila perlu, untuk menghasilkan audio yang diterjemahkan.

Pengenalan ucapan otomatis (ASR)
Otomatis Speech Recognition (ASR) dilakukan dengan menggunakan jaringan saraf (NN) sistem dilatih pada menganalisis ribuan jam masuk audio pidato. Model ini dilatih mengenai interaksi manusia dengan manusia daripada perintah manusia-ke-mesin, menghasilkan pengenalan ucapan yang dioptimalkan untuk percakapan normal. Untuk mencapai hal ini, lebih banyak data yang diperlukan serta DNN yang lebih besar daripada ASRs manusia ke mesin tradisional.
Pelajari lebih lanjut tentang Microsoft pidato ke layanan teks.
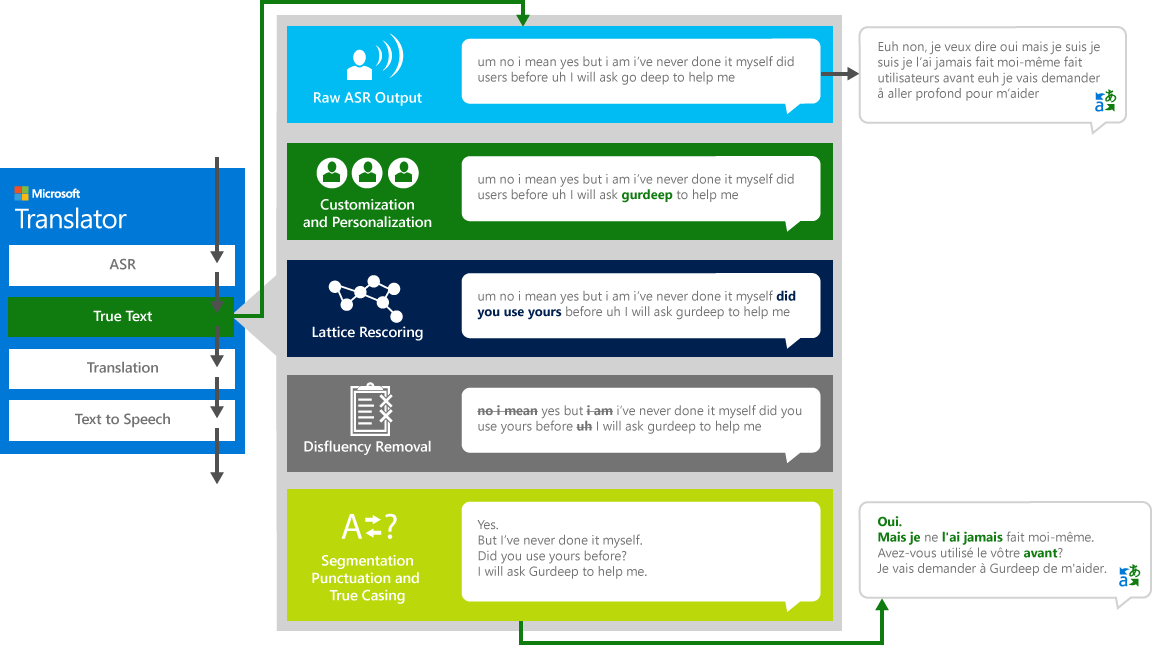
Dengan TrueText
Sebagai manusia berbicara dengan manusia lain, kita tidak bicara sebagai sempurna, jelas atau rapi seperti yang kita sering berpikir kita lakukan. Dengan teknologi TrueText, teks literal ditransformasikan untuk lebih mencerminkan maksud pengguna dengan menghapus disfluensi pidato (kata pengisi), seperti "UM", "Ah" s, "dan" s, "seperti" s, gagap, dan pengulangan. Teks ini juga dibuat lebih mudah dibaca dan diterjemahkan dengan menambahkan jeda kalimat, tanda baca yang tepat, dan kapitalisasi. Untuk mencapai hasil ini, kami menggunakan dekade kerja pada teknologi bahasa, kami mengembangkan dari Translator untuk membuat TrueText. Diagram berikut menggambarkan, melalui contoh kehidupan nyata, berbagai transformasi TrueText beroperasi untuk menormalkan teks literal ini.
Terjemahan
Teks ini kemudian diterjemahkan ke dalam salah satu bahasa dan dialek didukung oleh Translator.
Terjemahan menggunakan API terjemahan ucapan (sebagai pengembang) atau dalam aplikasi atau layanan terjemahan ucapan, didukung dengan terjemahan terbaru berbasis jaringan saraf untuk semua bahasa yang didukung ucapan-masukan (Lihat Sini untuk daftar lengkapnya). Model ini juga dibangun dengan memperluas saat ini, sebagian besar ditulis-teks yang terlatih terjemahan model, dengan lebih diucapkan-teks corpora untuk membangun model yang lebih baik untuk berbicara jenis percakapan terjemahan. Model ini juga tersedia melalui Kategori standar "ucapan" API terjemahan teks tradisional.
Untuk bahasa yang tidak didukung oleh terjemahan saraf, terjemahan SMT tradisional dilakukan.
Teks pidato
Jika bahasa target adalah salah satu dari 18 teks-ke-ucapan yang didukung Bahasa, dan kasus penggunaan memerlukan output audio, teks kemudian dikonversi ke output ucapan menggunakan sintesis ucapan. Tahap ini dihilangkan dalam skenario terjemahan ucapan-ke-teks.
Pelajari lebih lanjut tentang Microsoft teks untuk layanan bicara.
Penelitian
Lihat makalah penelitian terbaru dari tim penerjemah Microsoft.



