
Portare la traduzione ai Edge Device con Microsoft Translator
Nel novembre 2016, Microsoft ha portato il vantaggio di una traduzione automatica basata su intelligenza artificiale, alias neurale traduzione automatica (NMT), agli sviluppatori e agli utenti finali allo stesso modo. La settimana scorsa Microsoft ha portato la capacità NMT al limite del cloud sfruttando l'NPU, un processore dedicato AI ai integrato nella Il compagno 10, L'ultimo telefono di punta di Huawei. Il nuovo chip rende disponibili le traduzioni AI-Powered sul dispositivo anche in assenza di accesso a Internet, permettendo al sistema di produrre traduzioni la cui qualità è alla pari con il sistema online.
Per raggiungere questa svolta, ricercatori e ingegneri di Microsoft e Huawei hanno collaborato nell'adattamento della traduzione neurale a questo nuovo ambiente informatico.
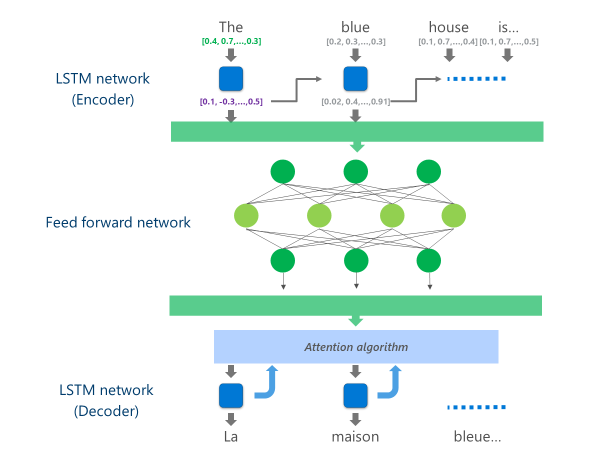
I sistemi NMT più avanzati attualmente in produzione (ad esempio, utilizzati su larga scala nel cloud da aziende e app) utilizzano un'architettura di rete neurale che unisce più livelli di Reti LSTM, un algoritmo di attenzione e un livello di traduzione (decoder).
L'animazione seguente spiega, in modo semplificato, come funziona questa rete neurale multi-layer. Per maggiori dettagli, si rimanda alla sezione "che cos'è la pagina di traduzione automatica"sul sito Microsoft Translator.

In questa implementazione NMT cloud, questi livelli medio LSTM consumano una grande parte della potenza di calcolo. Per poter eseguire il NMT completo su un dispositivo mobile, era necessario trovare un meccanismo che potesse ridurre questi costi computazionali preservando, per quanto possibile, la qualità della traduzione.
Questo è dove l'unità di elaborazione neurale di Huawei (NPU) entra in gioco. I ricercatori e gli ingegneri di Microsoft hanno approfittato della NPU, che è specificamente progettato per eccellere a calcoli di AI a bassa latenza, per offload operazioni che sarebbero state eccessivamente lento per elaborare sulla CPU principale.
Implementazione
L'implementazione ora disponibile nell'applicazione Microsoft Translator per Huawei Mate 10 ottimizza la traduzione eseguendo l'offload delle attività più intensive di calcolo per la NPU.
In particolare, questa implementazione sostituisce questi livelli di rete LSTM intermedi da un profondo frete neurale eed-forward. Deep feed-forward reti neurali sono potenti, ma richiedono grandi quantità di calcolo a causa dell'alta connettività tra i neuroni.
Le reti neurali si basano principalmente su moltiplicazioni di matrici, un'operazione che non è complessa da un punto di vista matematico, ma molto costosa se eseguita sulla scala necessaria per una rete neurale profonda. Il Huawei NPU eccelle nell'esecuzione di queste moltiplicazioni di matrice in modo massicciamente parallelo. È anche abbastanza efficiente dal punto di vista dell'utilizzo di potenza, una qualità importante sui dispositivi alimentati a batteria.
Ad ogni livello di questa rete di feed-forward, la NPU calcola sia l'uscita del neurone grezzo che la conseguente Funzione di attivazione ReLu in modo efficiente e con latenza molto bassa. Sfruttando l'ampia memoria ad alta velocità sulla NPU, esegue questi calcoli in parallelo senza dover pagare il costo per il trasferimento dei dati (ad esempio, rallentando le prestazioni) tra la CPU e l'NPU.
Una volta che viene calcolato il livello finale di questa rete Deep feed-forward, il sistema ha una rappresentazione ricca della frase della lingua di origine. Questa rappresentazione viene quindi alimentata attraverso un "decoder" LSTM da sinistra a destra per produrre ogni parola di lingua di destinazione, con lo stesso algoritmo di attenzione utilizzato nella versione online del NMT.
Come Di Anthony Aue, uno dei principali Software Development Engineer del team Microsoft Translator spiega: "prendendo un sistema che gira su potenti server cloud in un Data Center e l'esecuzione invariata su un telefono cellulare non è un'opzione praticabile. I dispositivi mobili hanno limitazioni nella potenza di calcolo, nella memoria e nell'utilizzo di energia che le soluzioni cloud non hanno. Avendo accesso alla NPU, insieme ad alcune altre modifiche architettoniche, ci ha permesso di aggirare molte di queste limitazioni e di progettare un sistema in grado di funzionare in modo rapido ed efficiente sul dispositivo senza dover compromettere la qualità della traduzione."

L'implementazione di questi modelli di traduzione sull'innovativo chipset NPU ha consentito a Microsoft e Huawei di fornire la traduzione neurale sul dispositivo a una qualità paragonabile a quella dei sistemi basati su cloud, anche quando si è fuori dalla rete.



