

数百万人のユーザー向けに Postgres と Citus を使用して構築された英国の新型コロナウイルス ダッシュボード
Open Source



本ポストは以下の記事の翻訳です。

公開日時: 2021 年 12 月 11 日 09:48 AM
新型コロナウイルス パンデミックの発生当初から、英国 (UK) 政府は、主要な健康指標を追跡し、これらの指標を国民と共有することを最優先事項としてきました。
また、何が起きているのかを理解しようとしていた英国の国民は情報に飢えていました。地図、グラフ、表がパンデミックの共通語となりました。この結果、GOV.UK Coronavirus ダッシュボードは、英国で最もアクセスされる公共サービス Web サイトの 1 つになりました。

UK Coronavirus ダッシュボードを頼りにしている人々はかなりの数になります。政府職員、公衆衛生当局者、医療従事者、ジャーナリスト、そして国民はみな、この同じサービスを利用しています。
オープン アクセス データの価値を示す良い例であるだけでなく、UK Coronavirus ダッシュボードはオープン ソースでもあります。すべてのソフトウェアおよび SQL クエリ自体も、GitHub の MIT license で提供されており、データも Open Government License 3.0 で利用できます。
アクセシビリティももう一つの重要な設計方針です。ダッシュボードはさまざまな障碍を持つ人用に設計されています。インターフェイスは簡単に使用でき、誰でもデータを操作して、特定の期間や地域での傾向を視覚化することができます。
この記事では、UK Coronavirus 分析ダッシュボードがどのようにして作成されることになり、またなぜこのようなアーキテクチャで設計されているかについて詳しく紹介します。また、ダッシュボードは拡張が必要なことから UKHSA チームが直面したデータベースの課題、そしてチームがどのように Azure、Azure Database for PostgreSQL マネージド サービス、および Postgres を分散データベースに変換する Citus の拡張機能を使用しているかについても紹介します。
UK Coronavirus ダッシュボードの誕生
初期の UK Coronavirus ダッシュボードは、ArcGIS を使用した簡単なダッシュボードでした。
これはすぐに単純な 1 ページのサービスで置き換えられました。2020 年 4 月に GOV.UK Coronavirus (COVID-19) ダッシュボードが最初にオンライン化された時点では (元の 2020 年 4 月 15 日のダッシュボードの英国公式アーカイブはこちら)、以下の 4 つの指標のみが含まれていました。
- 1 日の感染者数
- 累積感染者数
- 英国での 1 日の死亡者数
- 英国での累積死亡者数
この直後に、国民保険サービス (NHS) はアプリケーションを強化するために、英国保健省の執行機関である公衆衛生庁 (PHE、現在の名称は UKHSA) にプロジェクトを引き継ぎました。Pouria Hadjibagheri 氏が関わるようになったのはこの時点からです。
英国健康安全庁 (UKHSA、旧称は公衆衛生庁 PHE) の GOV.UK Coronavirus ダッシュボードの技術および開発リーダーが、データおよび Web サービス用ソフトウェア エンジニアリング部門の副部長である Pouria Hadjibagheri 氏です。Pouria 氏は 2020 年 4 月以来、英国でのコロナウイルス パンデミックの日々の統計を収集して公開する任務の技術サイドを率いてきました。
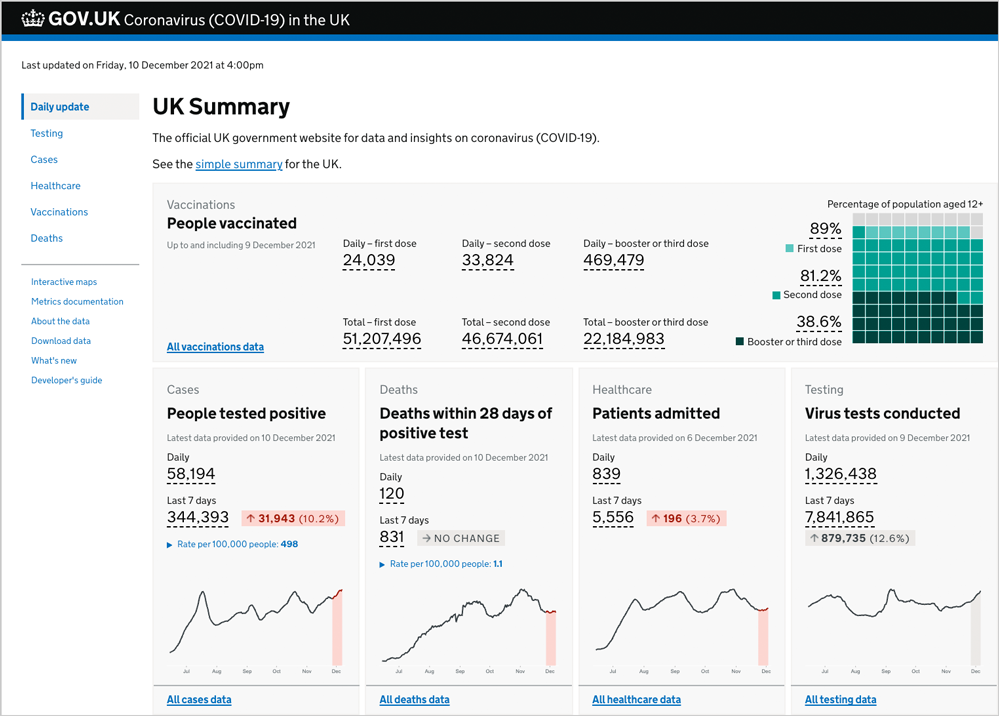
図 1: GOV.UK Coronavirus ダッシュボードの毎日更新されるページの 2021 年 12 月のスクリーンショット。ワクチン接種者数、感染者数、死亡者数、入院患者数、テスト実施数を示しています。このリアルタイム分析ダッシュボードは、GitHub で入手可能なオープン ソース ソフトウェアを使用し、Azure Database for PostgreSQL マネージドサービスの Hyperscale (Citus) オプション上で動作するように UKHSA チームにより構築されています。UK Coronavirus ダッシュボードは次の Azure サービスも使用しています。Azure Functions、Azure Cache for Redis、Azure App Service、Azure Front Door、Azure Service Bus、Azure Storage と Queue Storage、Azure Logic Apps、Azure API Management、Azure Event Grid、Azure Load Balancer、Azure Virtual Machine Scale Sets、Azure Container Registry、Azure DNS、Azure Virtual Network、Azure Service Principal、Azure Private Endpoint、Azure Monitor の Application Insights、および Azure DevOps と Bicep ファイル。
英国政府が毎日のコロナウイルスの状況報告でダッシュボードを使用し始めたとき
2020 年 6 月、Pouria 氏のチームは、アプリケーションを動かすためのよりスケーラブルなシステムの設計と考案の真っただ中でした。チームは、英国政府が毎日のコロナウイルスの状況報告で共有するスライドを置き換えるオンライン ダッシュボードを強化するように求められ、これを実現しました。
この時点で、1 日のピーク時のダッシュボードのオンライン ユーザー数は約 1,500 人でした。しかし、英国首相がダッシュボードの URL をツイートしたところ、突然ユーザー数が急増しました。
5 分以内に、ユーザー数は約 80,000 人まで急激に増加しました。それ以降、日々の平均ユーザー数は 30,000 ~ 40,000 人となり、その後も増え続けました。
翌年、Pouria 氏のチームは分析ダッシュボードを拡張し、新たな指標やより対話型の機能を追加しました。現在、アプリケーションの 1 日あたりのユニーク ユーザー数は平均で 100 万に上り、1 日あたり 7,000 万ヒットのアクセスを生んでいます。
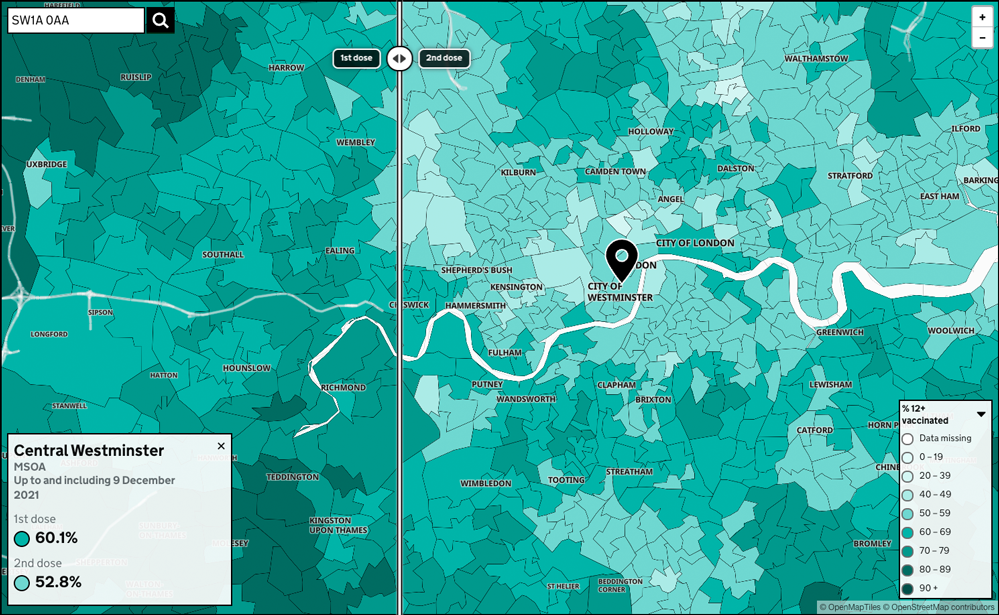
図 2: 毎日更新される、GOV.UK Coronavirus ダッシュボードのワクチン接種者数の対話型地図のスクリーンショット。この図は対話型であり、水平に移動できるスライダーで、1 回目の接種と 2 回目の接種のデータを比較できます。ダッシュボード上のマップとのやり取り時には、1 秒未満で 2 ~ 3 個の SQL クエリが実行されます。
https://coronavirus.data.gov.uk/details/interactive-map/vaccinations
時系列データ セット全体 (現在は 8 億行のデータ) を毎日更新
最初は、分析ダッシュボードには、記者会見、ツイート、NHS Web サイトで行われた発表などの少数のソースからのデータしか含まれませんでした。
プロジェクトが成長するにつれ、多くの分析アプリケーションと同様に、人々はさらに多くの質問への回答をダッシュボードに求めるようになりました。したがって、チームはさらに多くのソースからデータを収集し始めました。
現在は、病院がデータを NHS に報告し、NHS が UKHSA チームに報告しています。またチームは、以下のような取り決めを含む、多様なソースからデータを入手するための強固なリンクも確立しました。
- 英連邦の国家統計局からの死亡証明書に基づく統計情報
- 国民保険サービス (NHS)
- 保健省からのテスト データ
- 国家予防接種管理システムからのワクチン接種者数データ
- 公衆衛生当局からの感染者数と死亡者数データ
これらのデータの一部は午後 4 時にダッシュボードが更新される時点ですでに公開済みですが、大半の人は午後 4 時まで待ってからデータを使用しています。この主な理由が、UK Coronavirus ダッシュボードは、検証済みの十分に構造化された一貫したデータをダウンロードできるプラットフォームをユーザーに提供するためです。また情報は視覚化されており、ユーザーはまさに必要なデータを必要な形式でダウンロードできます。
この記事の公開時点では、分析ダッシュボードとその土台となるデータベースである Azure Database for PostgreSQL マネージド サービスは、さまざまなソースにより送信された約 8 億行からデータ パイプラインに集約された、5,500 万を超えるデータ ポイントを毎日処理しています。
UKHSA チームは、時系列データ セット全体も毎日更新します。各発表の正確性と整合性を保証するために、重複排除、修正、特定がデータ セット全体に対して行われます。
この結果、分散 PostgreSQL データベースには現在 75 億件を超えるレコードが存在します (一部はネストされた JSON ペイロードであるため、これは行数ではなくレコード数です)。レコードの総数は毎日 5,000 万件以上増えます。
データ ソース数とデータ量の増加と並行して、UKHSA チームは以下のような新しい重要な機能を分析ダッシュボードに追加しています。
- ダウンロード可能なデータ セット (過去の特定の日付に公開されたデータのどの部分でもダウンロード可能)
- 新しい視覚化
- 新しい検索機能
- 6 つの管理および医療カテゴリでの異なる粒度レベルでの対話機能
たとえば、郵便番号で検索することにより、テスト数、感染者数、ワクチン接種者数、入院患者数、および死亡者数のデータをすばやく確認できます。また、対話型地図を使用して、1 回目と 2 回目のワクチン接種率が最も高い地域を視覚化することもできます。
UK Coronavirus 分析ダッシュボードの「数値」一覧
この表の指標は、2021 年 12 月のこの記事の公開時点での UK Coronavirus ダッシュボードのサイズと規模を表しています。
| データの説明 | データ量 |
|---|---|
|
アクティビティの量 (2021 年 12 月 10 日現在)
|
|
|
1 日の平均ユーザー数
|
150 万
|
|
ピーク時の1 分あたりの同時接続ユーザー数
|
85,000 ~ 100,000
|
|
ピーク時に CDN をヒットするリクエスト数の中央値
|
25 万
|
|
1 日の合計リクエスト (ヒット) 数
|
7,800 万
|
|
1 週間のページビュー数
|
8,000 万
|
|
1 日のダウンロード数
|
780 万
|
|
データの量 (2021 年 12 月 10 日現在)
|
|
|
1 日に公開される指標数
|
215
|
|
1 日に公開される合計データ ポイント数
|
8,000 エリアに対して
5,500 万 |
|
PostgreSQL データベース内のレコード数
|
75 億
|
|
PostgreSQL データベース内の行数
|
59 億
|

図 3: Microsoft Azure ポータルからの指標のスクリーンショット。GOV.UK Coronavirus ダッシュボードにヒットしたリクエストの合計数 (y 軸) を時間別 (x 軸) で表し、Pouria 氏と UKHSA チームが新しいデータを公開する、毎日午後 4 時直後にリクエスト数が 10 倍と大幅に増加することを示しています。
高い同時接続性での拡張時のパフォーマンスの課題
現在、分析ダッシュボードを照会するユーザーの数は、新たなデータが公開される毎日午後 4 時にピークに達します。
午後 4 時直前の 1 分あたりの同時ヒット数は約 30,000 ですが、データが公開されるとすぐに、1 分あたり 250,000 ~ 300,000 ヒットまで増加します。このサービスは新たなリクエストをただちにキャッシュに格納するように設計されていますが、午後 4 時の毎日の公開時間には、新たなデータを利用できるようにするためにすべてのキャッシュがこの時点でフラッシュされるため、ほぼすべてのヒットがサーバーに送られます。
曜日および感染状況によって異なりますが、ピーク時の同時接続ユーザー数は 60,000 ~ 100,000 人になります。これは、実際の Web サイトを閲覧しているユーザーの数であり、3 つの API を使用しているユーザー数ではありません。
データベースの応答が少しでも遅ければ、ユーザーはそれを実感します。ほぼリアルタイムのクエリ応答を返すことが最も重要です。200 ミリ秒と 300 ミリ秒の違いにより、Web サイトの応答が速いかどうかが決まるのです。
- なぜわずか 100 ミリ秒の違いが特にピーク時に大事となるのか。非同期サービスのバックプレッシャーにより、追加の待機時間がパフォーマンスの問題の負のドミノ効果を引き起こすことがあります。非同期サービスには処理制限が設定されていますが、受信リクエストの数は増え続けます。最終的には、無視された受信リクエストはタイムアウトにより失敗します。状況はさらに悪化する可能性があります。増加した受信リクエストを処理するために処理時間が延び、これによりアプリケーション サーバー数の水平スケーリングが行われる可能性があります。新たなサーバーはそれぞれデータベースに対してより多くの接続を確立するため、データベースの負荷が増え、データベースが受信リクエストに応えることがさらに難しくなります。このようにしてドミノ効果が発生します。
- バックプレッシャーとは。同期サービスはシステムからの応答を待ってから次のリクエストを発行するため、追加のリクエストがある場合には必ずしもハードウェアをフルに活用できません。逆に、非同期サービスは待機せずにリクエストを発行するため、データベースの並列処理を活用できます。ただし、ハードウェアで処理できるよりも多くのリクエストを発行する可能性があり、これにより著しい減速や障害を発生させる可能性があります。この現象をバックプレッシャーと呼びます。したがって非同期サービスには、データベースに対する同時リクエストの総数を制限するなど、バックプレッシャーに対処するメカニズムが必要です。
11 か月前の 2021 年初頭、ダッシュボードを照会する同時接続ユーザー数が急増し続け、アプリケーションで深刻なパフォーマンスの問題が出始めました。
この高いレベルの同時接続性をサポートするために、チームは分散データベースが必要であると判断しました。問題はどの分散データベースを採用するかでした。
分散データベースの追求
2021 年 1 月、データベースを試し、多数のテストを実行した後、Pouria 氏は Azure Database for PostgreSQL マネージド サービスの Hyperscale (Citus) 上で動作するようにアプリケーションを移行することを決定しました。Hyperscale (Citus) では、Postgres 用の Citus の拡張機能を使用します。これは、Postgres を分散データベースに変換するオープン ソースの拡張機能です。
この記事の執筆時点では、チームが Azure に導入した Citus 分散データベース クラスターは高可用性用に HA 対応となっており、12 のワーカー ノードと合計で 192 の vCore、最大 1.5 TB のメモリ、および 24 TB のストレージを備えています。(Citus のコーディネーター ノードは 64 の vCore、256 GB のメモリ、1 TB のストレージを備えています。)
Postgres を選択した理由
Postgres を選択した理由は、Pouria 氏は、データベースの整合性、および Postgres のようなリレーショナル データベースで提供される、データの結合と集約機能を求めていたためです。また、NoSQL スタイルの大まかに構造化されたデータを処理できる多用途性も必要であり、これも Postgres が提供できるものでした。
PostgreSQL は以前から Pouria 氏が好んで使用していた RDBMS (リレーショナル) データベースでした。同氏とチームは、Postgres の核心での多くの経験があり、自信を持って使用することができました。
Python ORM のサポートが重要
Python には、PostgreSQL をサポートする、すぐに利用できる複数の Object Relational Management [ORM] ライブラリがあるため、チームはアプリケーションを Postgres に接続するためのアダプターまたはラッパーを作成する必要がありませんでした。
Postgres には実証済みのドライバーがあり、主要なすべての言語の主要なすべてのフレームワークによりサポートされ、また既存のツールを使用してデータベースおよびサード パーティ ツールに接続できます。このため、ただちにワークロードを減らすことができます。Postgres を Python とともに使用する場合、データベースで何かを行う場合に、毎回一から作り直す必要がありません。そして、動きの速いプロジェクトではこれは重要な考慮事項です。
スケーラビリティが重要な要件
PostgreSQL では、Citus の拡張機能を使用してデータベースを水平にスケールアウトすることができます。そして Azure では、Citus は Hyperscale (Citus) と呼ばれるマネージド サービスとして提供されます。
より多くのデータに対して増え続ける需要に対処するために、拡張できるデータベース、特にプロジェクトの要求に応じて拡張可能なデータベースが必要でした。
チームは、Citus で使用されているシャーディングの原理が、理解も導入も容易であると判断しました。Citus の堅牢性はすでに Citus を使用している他の組織からの肯定的な反応により実証済みでした。多くのテストとさまざまなデータベース オプションの比較の実行後、チームは Hyperscale (Citus) こそが必要としているソリューションであり、Postgres 用の Citus の拡張機能は分散形式でワークロードを支持できる、将来も有効なソリューションであると結論付けました。
高可用性 (HA) の必要性から UKHSA はクラウドでマネージド データベース サービスを使用
Coronavirus ダッシュボードは、一般の人々、市民団体のリーダー、医療従事者、病院、政府機関などがすべて頼りにする極めて重要なサービスであるため、信頼できるバックアップ、サポート、セキュリティ、および回復/復元機能を提供できるマネージド データベース サービスを使用する必要がありました。
UK Coronavirus ダッシュボードは Microsoft Azure の包括的なサービス スイートを利用
UKHSA チームは多数の Azure サービスを活用しています。これらの Azure サービスの一部は、他のクラウドでは提供されていません。つまり、Citus は Azure 上でのみマネージド データベース サービスとして提供されており、チームには自分たちでデータベースを展開および管理する時間も人員もありませんでした。ダッシュボードの構築に使用された Azure 独自のサービスのもう一つの例が、Azure Functions です。これは、分散ジョブをオーケストレーションするための Durable Functions を提供する、Azure のサーバーレス インフラストラクチャです。
そしてもちろん、24 時間 365 日のサポートも重要です。Azure のカスタマー サポートはいつでも何時でも対応が早く、頼りになります。
JSON および JSONB に対する Postgres でのサポートは人気があるだけではない
UKHSA チームの Postgres データベース (クラスター全体にデータベースを分散させるために Azure 上で Hyperscale (Citus) を使用しているため、実際には分散データベース) には、ネストされた JSON ペイロードも含め、約 75 億件のレコードが含まれます。
Postgres により、SQL のリレーショナルな側面を NoSQL データベースの柔軟性と本質的に組み合わせることができます。Pouria 氏のチームは、Postgres データベース内のすべての値を、JSON ペイロード (JSON オブジェクトまたは JSON アレイのいずれか) として格納しています。Postgres での JSON の形式とペイロードの扱い方、および GIN インデックスを使用して SQL クエリを最適化する機能をチームは高く評価しています。
オープン ソース、オープン データ、透明性が設計の指針
PostgreSQL がオープン ソースであることも重要な要因
このプロジェクトに取り掛かる際の Pouria 氏の条件の 1 つが、ソリューションがオープン ソースでなければならないということでした。多くのアプリケーションで、実際のコード ベースを見られるということは重要な要因です。このサービスは人々から信頼される必要があり、Pouria 氏にとっては、それは人々がコードを見られ、その質の高さを確認できることを意味していました。すべてがオープン ソースである必要がありました。
ダッシュボードのコード ベース全体がオープン ソースであり、これは主に Pouria 氏のオープン ソースの価値に対する信念によるものです。GitHub で 15 個の Coronavirus ダッシュボードのリポジトリが公開されています。UKHSA チームは世界中からコードのコントリビューションを受け、これらのコードはこの種のデータ収集および分析の専門家により徹底的に検討されました。
このオープン ソースの取り組みの結果: 国民に対する透明性、ダッシュボードへの信頼の向上、およびセキュリティの向上
透明性と言えば、Coronavirus ダッシュボードの [What’s new] ページで、Pouria 氏のチームが毎日取り扱っている内容を垣間見ることができます。このページには、データの問題、新たな指標、指標の変更などの更新情報が表示されます。
Citus もオープン ソースであることも助けに
Citus のオープン ソースをローカルで使用できることも重要な要因でした。Pouria 氏とチームが Citus 分散データベースを念頭に置いて書いたコードを、Docker コンテナーを作成し、コードをこのコンテナーで実行するだけでローカルで実行できることが有用でした。Citus がオープン ソースであることが、UKHSA チームが包括的でコンテナー化されたテスト スイートを開発することを可能にしました。
オープン ソース テクノロジ上で動作させるもう一つの利点は、コードで何が起きているかについての透明性が得られ、問題について GitHub で開発者に直接質問できるという点です。Pouria 氏は分析ダッシュボードの最適化と改良の取り組み時に、以下に示す問題を含む複数の問題を GitHub リポジトリで質問しました。Pouria 氏が質問した問題の大半は、GitHub ですでに解決しています。
- Altering (ENUM) types fails with err 57014 ((ENUM) タイプを変更するとエラー 57014 で失敗する)
- Failure to create composite indices on distributed tables that are partitioned (パーティション分割されている分散テーブルでコンポジット インデックスを作成できない)
- Dropping partition sets permanent lock & the partition never drops (パーティション セットをドロップすると永久ロックされ、パーティションがドロップされない)
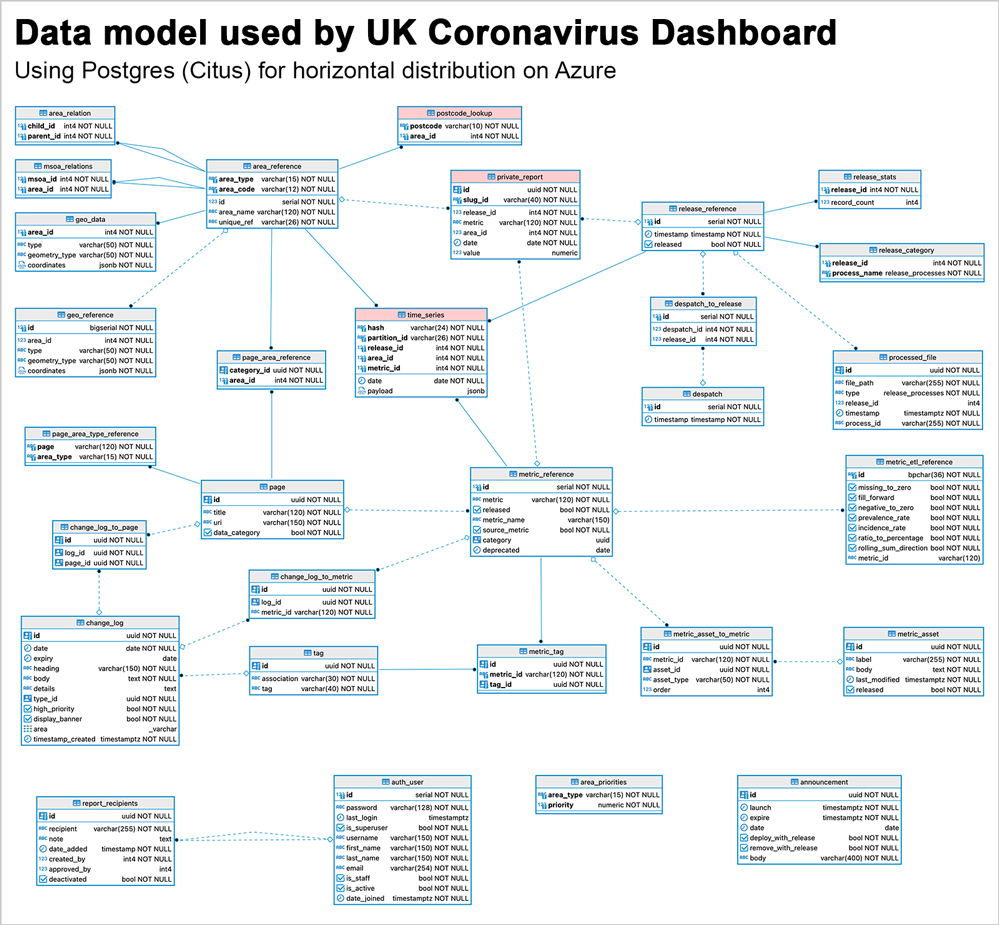
図 4: UK Coronavirus ダッシュボード チームが使用しているデータ モデルを示した図。このデータ モデルは高度にリレーショナルであり、time_series テーブルに JSONB ペイロードが含まれるという点で NoSQL の機能を活用しています。このデータ モデルでは、JSONB ペイコードは非常に頻繁かつ簡単に変更できるため、チームは将来のニーズに対応できる多用途性が得られます。ただし、全体的なリレーショナル データ モデルは変わらないため、不変のものに対してはデータの整合性が提供されます。Azure Database for PostgreSQL サーバー グループ全体で 3 つのテーブルを分散させるために、Hyperscale (Citus) が使用されています。
Postgres の範囲のパーティショニングと Citus のシャーディングの組み合わせによる時系列ワークロードの拡張
UKHSA チームは、データベース クラスター全体でデータおよびクエリを分散させる Citus の機能を活用することにより、1 秒未満のクエリ応答時間をユーザーに提供しながら、分析アプリケーションを拡張できました。または、Azure の用語を使用するのであれば、Hyperscale (Citus) サーバー グループ全体での分散によりこれを実現しました。
Citus での Postgres のシャーディングと分散に加え、チームは Postgres の範囲のパーティショニング機能も広く利用しています。現在、1 日分のデータはエリア タイプに基づいて 5 つの Postgres パーティションに分割されています。
分析ダッシュボードがデータベースにクエリを送信しても、時系列テーブル全体はクエリされず、関連性の高い Postgres パーティションのみがクエリされます。1,000 ~ 1,200 万行未満のパーティション[1] を直接ポイントすることにより、クエリ応答が大幅に加速されます。
シャーディング戦略: ディストリビューション列の選択
Citus のディストリビューション列 (シャーディング キーとも呼ばれる) に関しては、チームは独自の処理を行っており、データ モデル内に特に細かい列を作成しています。高速ハッシュ化のための BLAKE アルゴリズムを使用して、release_id、area_id、metric_id、および date の 4 つのフィールドから計算される 12 桁のハッシュ値を生成します。
このハッシュ値を使用してデータをクラスター全体に分散させることにより、Citus データベース クラスター内のノード間でほとんどの SQL クエリを並列処理することが可能になります。この結果、クエリ応答が速くなり、ダッシュボードの訪問者が期待する、迅速でほぼリアルタイムのエクスペリエンスを提供できるようになります。訪問者の対話型のクエリにより裏側であらゆる複雑な動作が起きていても、これが可能です。
同時に、ランダムな UUID などではなくハッシュを使用することにより、重複も防げます。ソースにより新しいバージョンが提供された場合など、データベースへの展開後にデータの更新が必要になることがあります。この場合、一貫したシャーディング キーがあれば、既存のデータの更新が可能になります。

図 5: パフォーマンスを最適化するために、SQL クエリに対して、親の時系列テーブルではなく、シャーディングされたパーティションが直接ポイントされます。UKHSA チームが使用している開発環境の 1 つである PyCharm での上記の SQL クエリの出力では、データベースに保存されているさまざまなペイロードのタイプを確認することができます。
複雑な SQL クエリのためのデータベース チューニングの詳細
Citus は Postgres 用の拡張機能であり、Postgres エコシステムのツールと互換性があるため、Hyperscale (Citus) への移行は容易でした。また、UKHSA チーム、特に Pouria 氏はすでに Postgres での豊富な経験がありました。
チームは、さまざまなマイクロサービスを異なるタイミングで統合することにより、Citus に徐々に移行することにしました。アップグレードは、1.5 か月余りの期間で、各マイクロサービスのコードを更新し、内部で展開するように計画されました。続いて、運用環境への展開前にデータの整合性を保証するために、サービスに対して大がかりな負荷テスト、またより幅広いダッシュボード チームのさまざまなメンバーによる細かな QA が実施されました。
UKHSA チームは移行とテストの真っ最中でしたが、UK Coronavirus 分析ダッシュボードで使用されているいくつかのより複雑なクエリ向けにパフォーマンス チューニングが必要であると判断しました。Pouria 氏はマイクロソフトの Postgres チームの Citus データベース エンジニアと協力して、パフォーマンスの最適化に取り組み、max_locks_per_transaction、max_adaptive_executor_pool_size、および task_assignment_policy に対する設定を調整することにより、データベースをチューニングしました。
トランザクションあたりの最大ロック数 (Max locks per transaction)
データベース クエリの複雑さという意味でサービスの最も負荷の高い部分である、ランディング ページと郵便番号検索ページを Citus 上で動作するように移行したところ、当初はかなり長い待機時間が見られました。ページが応答せず、表示に失敗することもありました。この場合、その後、データベースのすべてのトランザクションも失敗しました。調査の結果、生成されるロックの数が原因であり、場合によっては最大で 120,000 個のロックが発生していることが分かりました。これらのロックによりすべてが停止されていました。
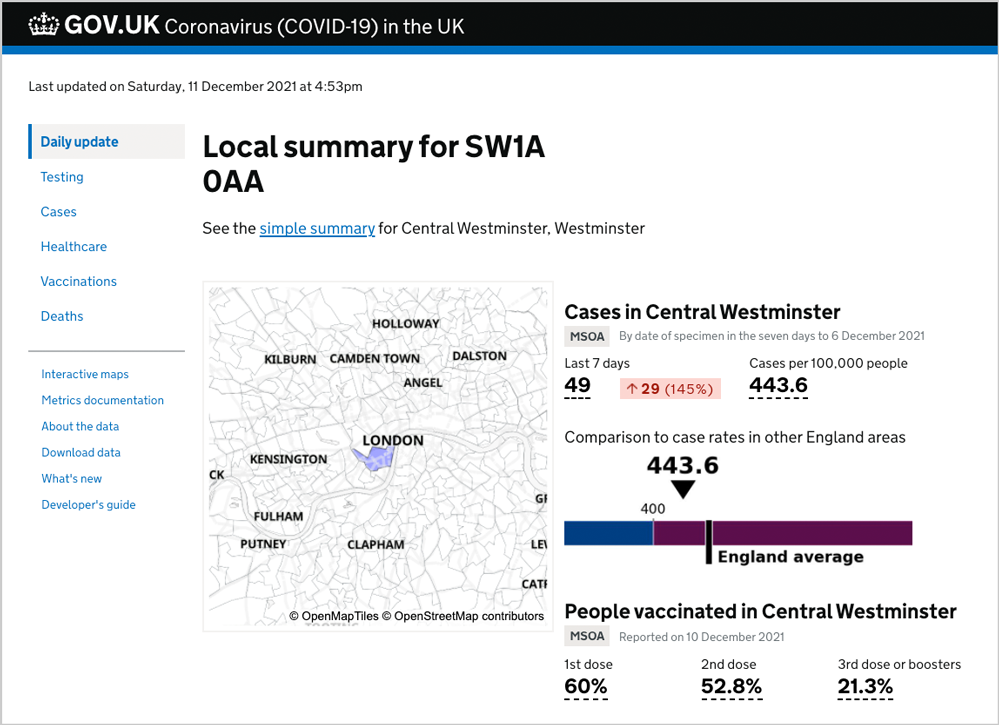
図 6: GOV.UK Coronavirus ダッシュボードの郵便番号ページ。ユーザーが英国の特定の郵便番号について、ローカルな統計情報の概要を確認でき、ダッシュボード サイトで最も負荷の高いページの 1 つです。これは、国会議事堂のあるウェストミンスターの SW1A 0AA に対するローカル郵便番号別概要ページです。いつでもこのページだけで、Azure Database for PostgreSQL の Hyperscale (Citus) は 12 個以上の SQL クエリを処理する必要があります。 (https://coronavirus.data.gov.uk/search?postcode=SW1A+0AA)
partition_id を使用したクエリが問題の一部であることが分かりました。API も含め、アプリケーションのどこからでも、クエリは常に 1 つのパーティションに送られていました。Citus にはこのような柔軟性があり、この機能により、特に大規模なデータベースで待機時間を短縮できます。ただしこの場合は、複数のエリア タイプからのデータが必要であるため、パーティションを直接クエリするのではなく、クエリでは partition_id が使用されていました。これが、至る所で多数のロックが発生していた理由の 1 つでした。
チームは、長い 250 行の SQL クエリをサブクエリに分割することから、この問題の対処を始めました。長い SQL クエリは、特定の郵便番号エリアの感染者数を提供するために使用されていましたが、これには一連の負荷の高い演算が必要でした。
サブクエリへの分割の目的は、これらのジョブを個々のワーカーやシャードにプッシュダウンすることでした。このために、チームはPostgres CTE (共通テーブル式) を使用するアプローチから、サブクエリ、およびサブクエリのサブクエリを使用するアプローチへと変更することを決定しました。
以下に、最適化の前と後、クエリのプッシュダウンなしとありの、SQL クエリの EXPLAIN 計画の対照比較を示します。通常/元のクエリと Citus 用に最適化されたクエリの両方に対する SQL クエリ全体 (および query_plan) は、Pouria 氏の GitHub の Gist で確認できます。
以下の Postgres のEXPLAIN 計画の対照比較で、次の点に注目してください。
- 左側の通常の query_plan はギザギザしています。
- 右側の最適化された query_plan は単純な波のようです。
これは、SQL クエリの最適化されたプッシュダウン バージョンでは、サブクエリ結果は Citus コーディネーター ノードに一度に 1 つずつ返されるのではなく、Citus のおかげで、並列化されて返されるためです。

図 7: ロックにより発生していた待機時間の問題に対処するために、UKHSA チームは郵便番号別の細かいデータを取得する、特に長い SQL クエリを分割する必要がありました。これは、最適化の前と後の SQL クエリに対する EXPLAIN 計画の対照比較です。
しかし、どれだけクエリをプッシュダウンして最適化しても、システムで処理できるよりも多くのロックが生成され続けていました。
解決策は、max_locks_per_transaction に対する PostgreSQL 設定の値を大きくすることでした。既定の 64 の代わりに、Citus と UKHSA チームは、設定をノードあたりのパーティション数に合わせた 10,000 に変更しました。これは、多数のパーティションを持つ親テーブルをクエリするとき、特にパーティションに時系列データが含まれる場合に Postgres で発生する問題です。この問題は、パーティションが Citus でシャーディングされている場合にはさらに増幅します。この場合、ロックの最大数を高い値に設定することが不可欠です。
クエリを最適化し、max_locks_per_transaction 設定を変更し、可能な場合には Postgres パーティションを直接クエリすることにより、生成されるロック数は大幅に減り、ピーク時でも通常は 400 個未満になりました。
アダプティブ エクゼキューターの最大プール サイズ (Max adaptive executor pool size)
特定のタイプの SQL クエリについては、Pouria 氏と Citus エンジニアは、Citus が現在のセッションで生成する接続数を制限するために citus.max_adaptive_executor_pool_size も調整しました。
Pouria 氏のシャーディング戦略では、単純なクエリと複雑なクエリのどちらも、すべての SQL クエリが Citus クラスター内の複数のノード上で並列処理されます。問題は、Citus がワーカー ノード間に複数の接続を作成しなければならないため、単純な短いルックアップ クエリの並列処理によりオーバーヘッドが追加されていることでした。
このため、チームは短いルックアップ クエリに対して、ノードごとの接続が 1 つになるように、citus.max_adaptive_executor_pool_size を 1 に設定しました。集約を実行するクエリなど、より負荷の高いクエリについては既定値の 16 に設定しました。
パフォーマンスを最適化する上で、どのタイプの SQL クエリにより多くの、または少ない接続を割り当てるべきかを優先順位付けできるこの Citus の柔軟性の活用は非常に効果的でした。
ラウンドロビンのタスク割り当てポリシー (Round-robin task assignment policy)
分析ダッシュボードでは、Citus を使用して以下の 3 つの Postgres テーブルを分散させています。
- 時系列テーブル (time_series)
- 郵便番号ルックアップ テーブル (postcode_lookup)
- 見出しデータのテーブル (private_report)
残りの Citus テーブルは、参照テーブルまたはコーディネーター ノードにローカルなローカル テーブルです。Citus では既定で、参照テーブルのクエリは、「最初のレプリカ」と呼ばれる最初のワーカー ノード上で実行されます。
Pouria 氏は、すべての参照テーブル クエリが同じノードをヒットしないように、citus.task_assignment_policy 設定を「round-robin」に変更しました。ラウンド ロビン ポリシーでは、各レプリカを交互に使用しながらタスクをワーカーに割り当てます。SQL クエリが Citus 参照テーブルに対するものである場合 (汎用 API の使用時に頻繁に発生)、クエリはクラスター上の最初のノードに送られ、続いて 2 番目のノードに送られます。最初のワーカー ノードだけでなく複数のワーカーを使用することにより、パフォーマンスが向上します。
大規模で応答の速いアプリケーションを構築するための見識
Pouria 氏は、膨大な量の時系列データを処理し、応答が速く感じられる 200 ミリ秒の応答時間でのユーザー エクスペリエンスを提供できるアプリケーションを構築する方法について、さらにいくつかの見識を共有してくれました。
原則に基づいた分析サービスの設計
新たなアプリケーションを迅速に提供しなければならないというプレッシャーは、簡単な方法でサービスを構築するよう組織を誘導することがあります。UK Coronavirus 分析ダッシュボードの場合は、データベースに対する適切な構造、またはコードに対する適切な構造を実装できないか、あるいはスケーリング可能なアプリケーションを設計できなければ、いずれ大きな問題を発生させていたでしょう。
データベースに対する適切な構造とは何でしょうか。ソフトウェア エンジニアリングにおけるあらゆることと同様に、これはプロジェクトの詳細によって異なります。今回は、Pouria 氏のチームは RDBMS 設計、データの整合性、接続プール、コードの多用途性と再利用性、およびデータの徹底的な理解のためのベスト プラクティスに従いました。実際、Pouria 氏にデータについての深い理解があったために、今後発生する可能性がある予想外のニーズに対応できるように、JSONB ペイロード (RDBMS と NoSQL との組み合わせ) を使用することを選択しました。
Pouria 氏とチームは開始当初、1 日に 100 万以上のユニーク ユーザー数に達し、1 日あたり 5,000 ~ 7,000 万のヒットに対応しなければならなくなるとは想定していませんでした。誰もこのレベルの成長や需要は予想していませんでしたが、Pouria 氏のチームは、将来のニーズに対応し、分散スケールを可能にするシステムを構築していました。これは、UK Coronavirus ダッシュボードの成功とインパクトに大きな影響をもたらす賢明な決断となりました。
データベース上の複数層のキャッシュの実装
毎日午後 4 時に UK Coronavirus ダッシュボードで発生するトラフィックの急増時に、応答性を向上させ、待機時間を減らすためにキャッシュが使用されています。
Pouria 氏のチームは、連携し、データベースに向けられる負荷を減らすように入念に計画された、複数層のキャッシュを使用しています。Azure Front Door が、事前に設定された期間に対するすべてのクエリ応答をキャッシュする CDN (コンテンツ配信ネットワーク) キャッシュとして使用されています。
また、Azure Cache for Redis を使用する API 管理 (APIM) レベルのキャッシュもあります。Pouria 氏は、各リクエストに対して一様の乱数を生成し、秒単位のその期間に対する応答をキャッシュするための、特別なポリシーを作成しました。これにより、数十万のキャッシュの期限が同時に切れてフラッシュされることを防ぐことができます。
別の Azure Cache for Redis が郵便番号の検索に使用されています。このキャッシュは、データが公開されている 6 つのエリア タイプすべてに郵便番号をマッピングする、郵便番号ルックアップ クエリの各部分が、Postgres データベースから 1 回しか要求されないようにします。郵便番号に対するリクエストは複数のエリアに分けられ、その後、非同期呼び出しが Redis に対して行われます。Redis にデータがない場合にのみ、リクエストがデータベースに転送されます。
最後に、Pouria 氏は CDN よりも短い、ブラウザー上のクライアント側キャッシュも使用しています。これらのキャッシュをすべて使用することは一般的な慣行ではないかもしれませんが、UK Coronavirus ダッシュボードの場合は、これらのキャッシュによりアプリケーションの応答性を維持しながら、提供されるデータの鮮度を保証できます。同一のクエリに対する有効期限は、キャッシュ層ごとに異なります。これにより、以下のことが保証されます。
- データの鮮度: クライアント側 (ブラウザー) のキャッシュの期間は 2 分を超えることはありません。これによりデータの鮮度が保証され、全般的なユーザー エクスペリエンスが向上します。
- 短期的負荷の軽減: Web サイトのデータは CDN でキャッシュされますが、この期間も 2 分を超えることはありません。CDN キャッシュをフラッシュするには最長で 10 分かかり、新しいデータの公開時にユーザーを大いに混乱させる可能性があるため、これは特に重要です。この 2 分の期間により、同一のリクエストがバックエンドに到達する頻度が低くなり、APIM と Redis サーバーの両方の負荷が減ります。
- 中期的負荷の軽減と偶発性への対応: 時系列データについては期間が 10 分~ 8 時間、汎用データについては最長で 2 週間である Redis キャッシュは、新しいデータが公開されるとただちに無効化される構造となっています。
- 大きなペイロードに対する長期的負荷の軽減: 数百万行のデータ セットを提供するダウンロード ページを動かしている APIv2 用のストレージ ベースのキャッシュは、同一リクエストが 1 回しか処理されないように、公開日に基づいて無期限に保持されます。
Azure Cache for Redis の事前入力済みキャッシュ
一部の大きくて複雑な SQL クエリに対する応答時間を約 920 ミリ秒から約 50 ミリ秒に短縮するために、データがクエリされる数分または数秒前に、約 9,000 個のキャッシュ項目が事前に入力されます。
大きな SQL クエリが複雑なのは、ページ上のすべての指標がすべてのエリアに対して毎日利用可能ではないためです。たとえば、イングランドのワクチン接種数データは MSOA[2] レベルで公開されていますが、スコットランドでは地方自治体レベルで公開されています。
これらのタイプの SQL クエリを事前の準備なしにサポートするには、多数 UNION や JOIN が必要になり、時間がかかりすぎます。計算のこの厄介な部分を事前に処理しておくことにより、これらの SQL クエリを Citus データベース クラスターのワーカー ノードにプッシュダウンし、並列処理することが可能になります。また、処理速度も速くなります。
Postgres の分散はスケーラビリティに不可欠
Azure Database for PostgreSQL を使用し、Hyperscale (Citus) により Postgres をノードのクラスター全体に分散させるという、Pouria 氏と UKHSA チームの決断は、GOV.UK Coronavirus ダッシュボードが数百万人のユーザーに対してより速い応答時間を実現することを可能にしました。これは、時系列データ セットが増え続けても可能です。
Citus によってクラスター全体に分散されたこの PostgreSQL データベースに含まれる 75 億件の (そして増え続けている) レコードを持つ UK Coronavirus ダッシュボードでは、一部のクエリは 3 ミリ秒未満で実行されます。Azure 上の Citus が提供するほぼ瞬時のパフォーマンスの別の例として、クエリをトリガーし、10 秒未満で 500 万を超えるデータ ポイントを返す LTLA データ セットをダウンロードできることが挙げられます。
UK Coronavirus ダッシュボードで処理されるデータの種類は、時系列であり、大量であり、わずか数行を対象とした複雑なクエリをリアルタイムで処理することが必要なため、データベースのデータで最も負荷の高いものの 1 つであると、Pouria 氏は感じています。このトランザクションの規模での時系列データおよび各応答でのこのデータの量を扱うことはまれです。各トランザクションに関わる Postgres データベース処理の数およびデータの量を、Pouria 氏は「とてつもなく膨大」という言葉で表しています。結論として、この量を処理できるのであれば、Citus はどのような量のデータも処理できるでしょう。
謝辞
このブログの執筆への協力および GOV.UK Coronavirus ダッシュボードの構築にかかった労力とその広範囲な影響に関して、このプロジェクトに参加した、UKHSA (旧称 PHE) およびマイクロソフトの Postgres と Citus チームの個々のチームメート全員に心から感謝の意を表したいと思います。それぞれの貢献および協力なしでは、現在稼働している分析ダッシュボードの構築は不可能でした。特に以下の方々に感謝いたします。
* Clare Griffiths 氏 – UKHSA の UK Coronavirus ダッシュボード部門の部長
* David Jephson 氏 – UKHSA の UK Coronavirus ダッシュボード部門の副部長 (データとパイプライン担当)
* James Westwood 氏 – UKHSA の UK Coronavirus ダッシュボード部門の副部長 (データとパイプライン担当)
* Brogan Goble 氏 – UKHSA のソフトウェアおよび DevOps エンジニア
…
* Marco Slot 氏 – マイクロソフトの Citus データベース エンジンの技術リーダー兼プリンシパル エンジニア
* Sai Srirampur 氏 – マイクロソフトの Citus カスタマー エンジニアリングの技術リーダー兼プリンシパル エンジニアリング マネージャー
— また、共同執筆者の Pouria Hadjibagheri 氏と Claire Giordano 氏にも心から感謝いたします。
脚注
- Postgres は、パーティション分割されている親テーブルのクエリを可能にします。クエリ内に適切なフィルターが指定されていれば、Postgres により自動的に SQL クエリが適切なパーティションに送信され、実行されます。多くの Postgres ユーザーが、この方法で Postgres のパーティショニング機能を活用しています。GOV.UK Coronavirus ダッシュボードの場合は、UKHSA チームは、パフォーマンス最適化の手段として、余分な計画オーバーヘッドを減らすためにパーティションを直接クエリすることを選択しました。↩
- MSOA: Middle-Layer Super Output Area とは、2011 年頃の作成時に、それぞれ最大で約 5,000 人の住民が居住していた統計的境界です。各 MSOA に対する推計人口は国家統計局により毎年更新されています。↩
