

Genoa-X CPU を使用した HBv4/HX シリーズ VM のパフォーマンスとスケーラビリティ
Azure – HPC



オリジナル投稿者 Rachel Pruitt
執筆協力者: Amirreza Rastegari、Jon Shelley、Scott Moe、Jie Zhang、Jithin Jose、Anshul Jain、Jyothi Venkatesh、Joe Greenseid、Fanny Ou、Evan Burness
本投稿は以下、ブログ投稿の翻訳記事です。
Performance & Scalability of HBv4 and HX-Series VMs with Genoa-X CPUs (microsoft.com)
Azure において、ハイパフォーマンス コンピューティング (HPC) 向けの仮想マシン (VM) シリーズである Azure HBv4 シリーズと Azure HX シリーズの一般提供を発表しました。この記事では、これらの HPC に最適化された VM の技術面とパフォーマンス面の詳細情報を紹介します。
2022 年 11 月に発表されたプレビューの間、これらの VM には標準の第 4 世代 AMD EPYCTM プロセッサ (コードネーム “Genoa”) を搭載していました。本日発表した一般提供により、すべての HBv4/HX シリーズ VM は、AMD 3D V-Cache 搭載の第 4 世代 AMD EPYCTM プロセッサ (コードネーム “Genoa-X”) にアップグレードされました。HBv4/HX シリーズ VM では、標準の第 4 世代 AMD EPYC プロセッサを利用できなくなります。
これらの VM では、以下のような HPC 向けの最新テクノロジが採用されています。
- AMD 3D-V Cache 搭載の第 4 世代 AMD EPYC CPU (コードネーム “Genoa-X”)
- VM あたり 2.3 GB の L3 キャッシュ
- 最高 780 GB/秒の DDR5 メモリ帯域幅 (STREAM TRIAD)、最高 5.7 TB/秒の 3D V-Cache 帯域幅 (STREAM TRIAD)、最高 1.2 TB/秒の実行 (混合) 帯域幅
- 400 Gbps NVIDIA Quantum-2 InfiniBand
- 80 Gb/秒の Azure 高速ネットワーク
- 最高 12 GB/秒 (読み取り) および 7 GB/秒 (書き込み) のストレージ帯域幅を実現する 3.6 TB のローカル NVMe SSD
HBv4/HX – VM サイズの詳細 & 技術仕様
HBv4/HX シリーズの VM は、それぞれ以下の表 1 と表 2 に示されているサイズおよび仕様で提供されます。既存の H シリーズの VM と同様、HBv4/HX シリーズにも、さまざまな 仮想コア数の VM サイズがあり、VM あたりのパフォーマンスが最大のサイズから、コアあたりのパフォーマンスが最大のサイズまで、さまざまなサイズから選択できるようになっています。
|
VM Size |
176 CPU |
144 CPU |
96 CPU |
48 CPU |
24 CPU |
|
VM Name |
standard_HB176rs_v4 |
standard HB176-144rs_v4 |
standard HB176-96rs_v4 |
standard HB176- 48rs_v4 |
standard HB176-24rs_v4 |
|
InfiniBand |
400 Gbps Quantum-2 (NDR) |
||||
|
CPU |
AMD EPYC 9V33X codenamed Genoa-X |
||||
|
Peak CPU Frequency |
3.7 GHz* |
||||
|
RAM per VM |
688 GB |
||||
|
RAM per core |
4 GB |
5 GB |
7.5 GB |
15 GB |
30 GB |
|
Memory B/W per VM |
DRAM: 780 GB/s (STREAM TRIAD) |
||||
|
Memory B/W per core |
6.8 GB/s |
8.3 GB/s |
12.5 GB/s |
25 GB/s |
50 GB/s |
|
L3 cache per VM |
2304 MB |
||||
|
L3 Cache per core |
13 MB |
16 MB |
24 MB |
48 MB |
96 MB |
|
SSD perf per VM |
2 x 1.8 TB NVMe – total of 12 GB/s (Read) / 7 GB/s (write) |
||||
表 1: HBv4 シリーズ VM の技術仕様
|
VM Size |
176 CPU cores |
144 CPU cpres |
96 CPU cores |
48 CPU cores |
24 CPU cores |
|
VM Name |
standard_HX176rs |
standard_HX176-144rs |
standard HX176-96rs |
standard_HX176-48rs |
standard_HX176-24rs |
|
InfiniBand |
400 Gbps NDR |
||||
|
CPU |
AMD EPYC 9V33X codenamed Genoa-X |
||||
|
Peak CPU Frequency |
3.7 GHz* |
||||
|
RAM per VM |
1.4 TB |
||||
|
RAM per core |
8 GB |
10 GB |
15 GB |
29 GB |
59 GB |
|
Memory B/W per VM |
DRAM: 780 GB/s |
||||
|
Memory B/W per core |
6.8 GB/s |
8.3 GB/s |
12.5 GB/s |
25 GB/s |
50 GB/s |
|
L3 Cache per VM |
2304 MB |
||||
|
L3 Cache per core |
13 MB |
16 MB |
24 MB |
48 MB |
96 MB |
|
SSD Perf per VM |
2*1.8 TB NVMe – total of 12 GB/s (Read) / 7 GB/s (write) |
||||
表 2: HX シリーズ VM の技術仕様
注: 最高クロック周波数 (FMAX) は、AMD EPYC 9004 シリーズ プロセッサを使用して Azure HPC チームが測定した AVX 以外のワークロードのシナリオに基づいています。実際のクロック周波数は、アプリケーションの演算強度 (SIMD) や並列度をはじめとする、さまざまな要素の作用を受けます。
詳細については、HBv4 シリーズおよび HX シリーズ VM に関する公式ドキュメントを参照してください。
第 4 世代 EPYC CPU の 3D-V Cache が HPC パフォーマンスに及ぼす影響
3D V-Cache と呼ばれるスタックド L3 キャッシュ テクノロジや、このテクノロジが広範な HPC ワークロードにどのような影響を及ぼすのか 理解しておくことは重要です。
まず、3D V-Cache 搭載の第 4 世代 EPYC プロセッサは、Genoa コア、CCD、ソケット、サーバーあたりの L3 キャッシュ メモリが標準の第 4 世代 EPYC プロセッサの 3 倍であるという点のみが異なります。これにより、2 ソケット サーバー (HBv4/HX シリーズ VM が土台としているサーバーなど) の合計は以下のようになります。
- (24 CCD/サーバー) x (96 MB L3/CCD) = 2304 MB の L3 キャッシュ/サーバー
|
CPU |
Xeon 2690 v4 (Broadwell) |
Xeon Gold 6148 (Skylake) |
Xeon 8280 (Cascade Lake) |
EPYC 7742 (Rome) |
EPYC 7V73X (Milan-X) |
EPYC 9004 (Genoa) |
EPYC 9V33X (Genoa-X) |
|
cores/2S Server |
28 |
40 |
56 |
128 |
128 |
192 |
192 |
|
L3 cache/2S server |
70 MB |
55 MB |
77 MB |
512 MB |
1,536 MB |
768 MB |
2,304 MB |
|
Relative size |
1x |
0.8x |
1.1x |
7.3x |
22x |
11x |
33x |
表 3: 過去 5 年間の複数世代の CPU にわたって 2 ソケット サーバーの L3 キャッシュを比較
関連する要素を考慮せずに L3 キャッシュ サイズだけに目を向けると、認識を誤る可能性があるので注意してください。CPU ごと、また世代ごとに、L2 (高速) と L3 (低速) の比率の配分が異なります。たとえば、Intel Xeon “Broadwell” CPU は、Intel Xeon “Skylake” コアよりもコアあたりの L3 キャッシュが (多くの場合 CPU あたりでも) 多いですが、メモリ サブシステムのパフォーマンスがより高いわけではありません。Skylake コアの L2 キャッシュは Broadwell CPU よりも大きく、また DRAM からの帯域幅も広くなっているうえ、プリフェッチ機能にも大きな進展がありました。上の表は、単に、Genoa-X サーバーの L3 キャッシュの合計サイズが以前の CPU と比べてどのくらい大きいかを示す目的で作成されたものです。
このサイズのキャッシュにより、(1) 有効メモリ帯域幅および (2) 有効メモリ待機時間を大幅に改善することが可能です。メモリ帯域幅やメモリ待機時間の改善により、多くの HPC アプリケーションで部分的または全面的にパフォーマンスが向上するため、Genoa-X プロセッサが HPC のお客様に及ぼす潜在的影響は大きいと言えます。これらのカテゴリに分類されるワークロードの例を以下に示します。
- 数値流体力学 (CFD) – メモリ帯域幅による制約が大きい
- 気象シミュレーション – – メモリ帯域幅による制約が中程度
- 陽解法有限要素解析 (FEA) – – メモリ帯域幅による制約が大きい
- EDA RTL シミュレーション – – メモリ帯域幅による制約が大きい
ただし、これらの大規模なキャッシュの影響を受けない対象について理解することも同様に重要となります。具体的には、ピーク FLOPS、クロック周波数、メモリ容量は改善しません。したがって、これらの 1 つまたは複数の要因によってパフォーマンスまたは実行自体が制限されるワークロードについては、一般的に Genoa-X プロセッサに搭載されている超大規模な L3 キャッシュの影響をあまり受けません。これらのカテゴリに分類されるワークロードの例を以下に示します。
- EDA フル チップ設計 – 大容量メモリ
- EDA レイアウト寄生抽出 – クロック周波数
- 陰解法有限要素解析 (FEA) – 高密度計算
一部の計算集約型ワークロードでは若干のパフォーマンス低下が見られました。これは、3D V-Cache を構成する SRAM が大きいため、周波数を上げるために CPU コア自体に向けられたはずの電力を CPU SoC に割り当てられた固定電力から振り分けてしまったことが原因です。これほど計算処理による制約を受けるワークロードはめったにありませんが、3D V-Cache がすべての HPC ワークロードのパフォーマンスを向上させる機能だと誤解せずに理解しておくことは有益です。
マイクロベンチマーク パフォーマンス
このセクションでは、HBv4/HX シリーズ VM のメモリ サブシステムと InfiniBand ネットワークのパフォーマンス特性を明らかにするマイクロベンチマークに焦点を当てます。
メモリ パフォーマンス
3D V-Cache 搭載の第 4 世代 AMD EPYC CPU を採用しているサーバーの “メモリ パフォーマンス” のベンチマークは、大容量 L3 キャッシュの影響が変化するとともに潜在的に大きいため、繊細なテストとなります。
まずは、DRAM と L3 という 2 種類のメモリのパフォーマンスを独立に測定して、2 つの値の間に大きな違いがあることを明確にしましょう。
この情報を得るために、業界標準の STREAM ベンチマークを、(A) 主にシステム メモリ (DRAM) に収まるようにサイズ調整した条件と、(B) 大容量 L3 キャッシュ (3D V-Cache) に全体が収まるように意図的にサイズを小さくした条件の両方で実行しました。
下の図 1 は、データ サイズ (8.9 GB) が大きすぎて L3 キャッシュ (2.3 GB) に収まらない HBv4/HX VM で業界標準の STREAM ベンチマークを実行した結果を示したものです。つまり、主に DRAM のパフォーマンスを表すメモリ帯域幅が計測されています。
この STREAM ベンチマークは、次のコマンドを使用して実行しました。
OMP_PLACES=”0,4,8,12,16,20,24,28,32,36,38,42,44,48,52,56,60,64,68,72,76,80,82,86,88,92,96,100,104,108,112,116,120,124,126,130,132,136,140,144,148,152,156,160,164,168,170,174” OMP_NUM_THREADS=48 ./stream
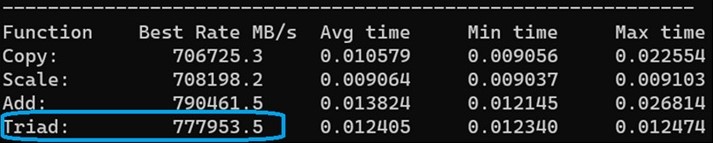
図 1: 3D V-Cache 使用の HBv4/HX シリーズ VM、9.6 GB データ サイズでの STREAM メモリ ベンチマーク
上記の結果は、プレビュー版の HBv4/HX VM (“Genoa-X” プロセッサ使用の GA 版 HBv4/HX VM で置き換え済み) など、“Genoa” プロセッサ搭載の標準 2 ソケット サーバーから、チャネルあたり 1 DIMM の構成で測定した結果と本質的に同じものです。前述のとおり、これは、ベンチマークのごく一部のみが 3D V-Cache に収まるようにテストを十分に大きくすることで、メモリ帯域幅に対する 3D V-Cache の影響を最小限に抑えているためです。上記の 約 780 GB/秒という結果は、標準の第 4 世代 EPYC CPU で実行した場合と比較して、これらのサーバーの物理 DIMM に差がないため、期待どおりの帯域幅となっています。
一方で、下の図 2 は、HBv4/HX シリーズ VM の 2.3 GB の L3 キャッシュに、より正確には CCD スライスあたり 96 MB の各 L3 に全体が収まるよう小さくしたデータセット (約 80 MB) で STREAM を実行した結果を示しています。ここでは、この STREAM ベンチマークを、次のコマンドで実行しました。
OMP_NUM_THREADS=176 ./stream

図 2: 2.3 GB の L3 キャッシュ (3D V-Cache) に全体が収まる HBv4/HX シリーズ VM での STREAM メモリ ベンチマーク
上の図 2 からは、ワーキング データセットのすべてまたは大部分が実行できるような大きさの L3 キャッシュを搭載していない、標準の第 4 世代 EPYC CPU やその他の CPU の結果よりも、測定帯域幅が大幅に広くなっていることがわかります。ここで測定された約 5.7 テラバイト/秒という STREAM TRIAD の帯域幅は、基本的に DRAM の帯域幅を表している図 1 の結果の 7 倍以上になっています。
では、どちらの数値が “正しい” のでしょうか。その答えは、“場合によってどちらも” です。以下の理由から、どちらの測定値も正確だと言えます。
- 各数値とも、測定された再現性のある結果であり、帯域幅の能力を正確に反映し、かつ、
- 各数値とも、実際にある現実世界のワークロードの HPC シナリオに沿ったものであるため、アプリケーションでの実効帯域幅は当該モデルの状況 (データセット) と実行場所の規模に強く依存します。
- 例 1: 一部のワークロードは、その性質上、数百ギガバイトのメモリを消費するため、実効帯域幅に対する 2.3 GB の 3D V-Cache の影響は最小限になっています。
- 例 2: 他のワークロードは、そもそも 1 台の最新型サーバー (VM) にとっても小さいか、サーバー (VM) あたりのメモリを減らすという強力なスケール アウトができるため、各サーバー上で DRAM ではなく L3 で実行されるデータの割合が増加します。このような場合、実効メモリ帯域幅は大幅に増幅されています。
後半のアプリケーション パフォーマンスのセクションでは、OpenFOAM のような強いメモリ帯域幅律速のアプリケーションで標準の第 4 世代 EPYC CPU に比べて最大 49% の向上が測定されたことから、3D V-Cache の効果を確認できます。これは当該モデルの特性に厳密に従っています。
したがって、私たち自身が再現性よく測定できたパフォーマンス データに基づくと、3D V-Cache による増幅効果は、実効メモリ帯域幅を最大 1.49 倍にすることだと言えます。これは、ワークロードが約 1.2 TB/秒 (約 780 GB/秒の 1.49 倍) の実効メモリ帯域幅を与えられているようにパフォーマンスを発揮するためです。
繰り返しますが、以下のデータは、キャッシュから実行されるアクティブなデータセットの割合の増加とパフォーマンス向上が密接に関係していることを示しているため、メモリ帯域幅の増幅効果は “最大値” として理解しておく必要があります。さらに、最高パフォーマンス向上に関する Azure の説明は、第 4 世代 AMD EPYC CPU の 3D V-Cache の有無でのパフォーマンス比較を大規模化するにつれて増していく可能性があります。
InfiniBand ネットワークのパフォーマンス
HBv4/HX VM は、最新の 400 Gbps NVIDIA Quantum-2 InfiniBand (NDR) ネットワークを搭載しています。以下のコマンドを使用して、2 台の HBv4 シリーズ VM に対して業界標準の IB パフォーマンス テストを実施しました。
一方向帯域幅:
双方向帯域幅:
これらのテスト結果は、以下の図 3 と図 4 に示されています。
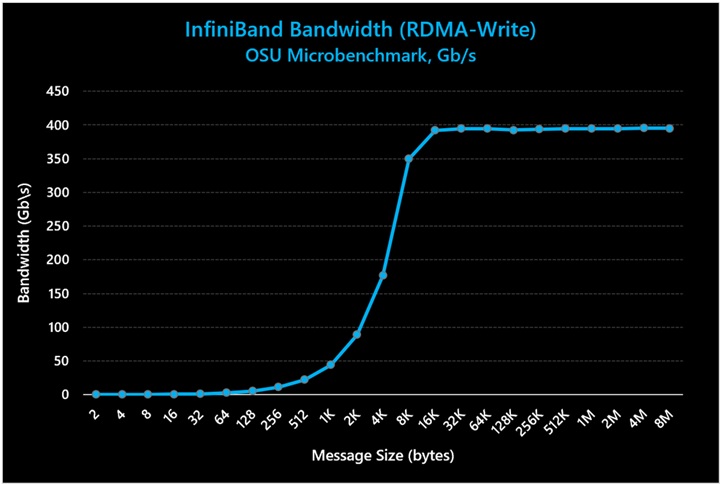
図 3: InfiniBand の一方向帯域幅が、最大帯域幅の想定値である 400 Gb/秒に達している
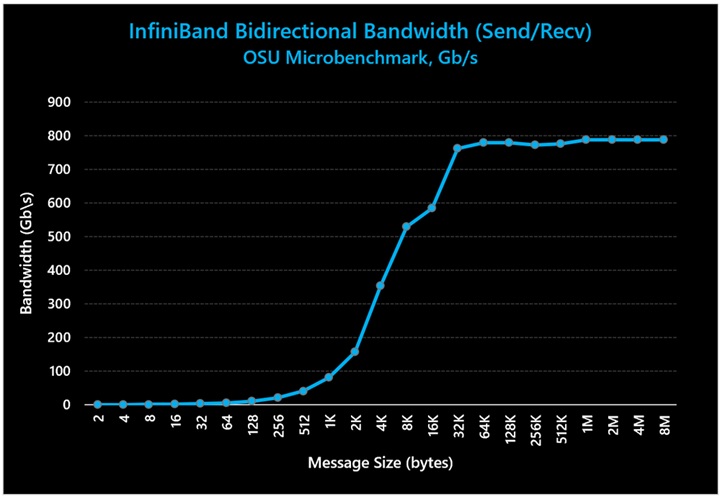
図 4: InfiniBand の双方向帯域幅が、最大帯域幅の想定値である 800 Gb/秒に達している
上の図で示されているように、Azure HBv4/HX シリーズ VM は、一方向と双方向の両方のテストでラインレートの帯域幅パフォーマンス (ピーク値の 99%) を達成しています。
アプリケーション パフォーマンス
このセクションでは、一般的に実行される HPC アプリケーションにおける HBv4/HX VM のパフォーマンス特性について取り上げます。また、Azure で提供されている、他のさまざまな HPC VM とのパフォーマンス比較も行います。比較する VM には以下が含まれます。
- 3D V-Cache 搭載の 176 コア第 4 世代 AMD EPYC CPU (“Genoa-X”) を使用した Azure HBv4/HX (HBv4 の完全な仕様、HX の完全な仕様)
- 176 コアの標準第 4 世代 AMD EPYC CPU (3D V-Cache なし) (“Genoa”) を使用した Azure HBv4/HX
- 3D V-Cache 搭載の 120 コア第 3 世代 AMD EPYC CPU (“Milan-X”) を使用した Azure HBv3 (完全な仕様)
- 120 コアの第 2 世代 AMD EPYC CPU (“Rome”) プロセッサを使用した Azure HBv2 (完全な仕様)
- 44 コアの第 1 世代 Intel Xeon Platinum (“Skylake”) を搭載した Azure HC (完全な仕様)
注: ここでは HC シリーズが、お客様との関連性が高い比較対象の 1 つとして用いられています。市場全体の HPC ワークロードの大部分は依然として、主に (または完全に) オンプレミスのデータセンターや、平均運用期間が 4 ~ 5 年のインフラストラクチャで実行されています。したがって、お客様が普段からオンプレミスで使用されているであろうあらゆる製造時期のマシンと整合する HPC テクノロジのパフォーマンス情報を含めることが重要になります。Azure HC シリーズ の VM は、使用されている中で最も古い世代のマシンに相当するマシンであり、お客様の当時の HPC 関連投資や構成の選択肢として主流を占めていた、EDR InfiniBand、1DPC DDR4 2666 MT/秒メモリ、第 1 世代 Xeon Platinum CPU (“Skylake”) などのハイ パフォーマンス テクノロジを備えています。そのため、以降のアプリケーション パフォーマンスの比較では、約 4 年前に製造された、HPC 向けに最適化されたサーバーに相当するマシンとして、HC シリーズが共通で使用されています。
注: 標準の第 4 世代 AMD EPYC CPU は、プレビュー版の HBv4/HX シリーズ VM でのみ利用できたものであり、現在は提供されていません。一般提供以降、HBv4/HX VM で使用できるのは、3D V-Cache 搭載の第 4 世代 EPYC プロセッサ (コードネーム “Genoa-X”) のみとなります。
特に記載がない限り、下記のすべてのテストは以下の構成で実施されているものとします。
- Alma Linux 8.6/8.7 HPC OS (Azure Marketplace と GitHub で提供)
- HPC-X MPI 2.15
数値流体力学 (CFD)
Ansys Fluent
注: すべての ANSYS Fluent テストで、HBv4/HX のパフォーマンス データ (3D V-Cache ありとなしの両方) は AlmaLinux 8.6 上の ANSYS Fluent 2022 R2 と HPC-X 2.15 で収集しましたが、他の結果は CentOS 8.1 上の ANSYS Fluent 2021 R1 と HPC-X 2.83 で収集しました。なお、新しいバージョンのソフトウェアを使用することによるパフォーマンス上の既知のメリットはありません。ANSYS、NVIDIA、AMD の各社での検証範囲の都合により、新旧のバージョンが使用されました。
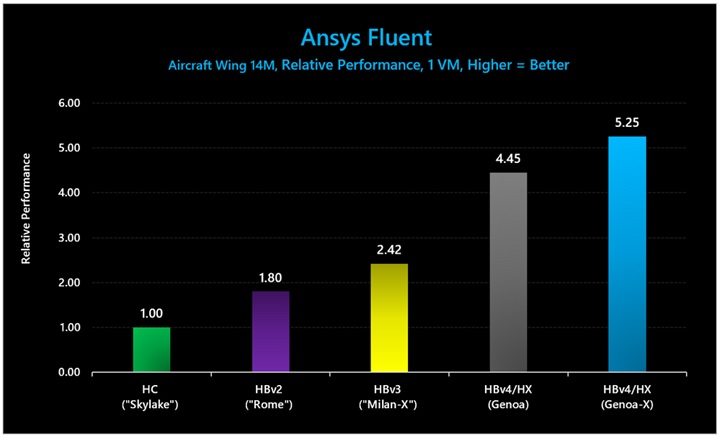
図 6: Ansys Fluent (Aircraft Wing 14M) では、3D V-Cache ありの HBv4/HX VM のパフォーマンスは、3D V-Cache なしの HBv4/HX VM の 1.18 倍、HBv3 シリーズの 2.17 倍でした。
|
VM Type |
Average Solver Rating |
|
HC-series |
729.77 |
|
HBv2 |
1314.27 |
|
HBv3 |
1764.8 |
|
HBv4/HX |
3247.7 |
|
HBv4/HX (with 3D V-Cache) |
3832.9 |
表 4: Ansys Fluent (Aircraft Wing 14M) における絶対パフォーマンス (ソルバー評価の平均。数値が大きいほど優れている)。
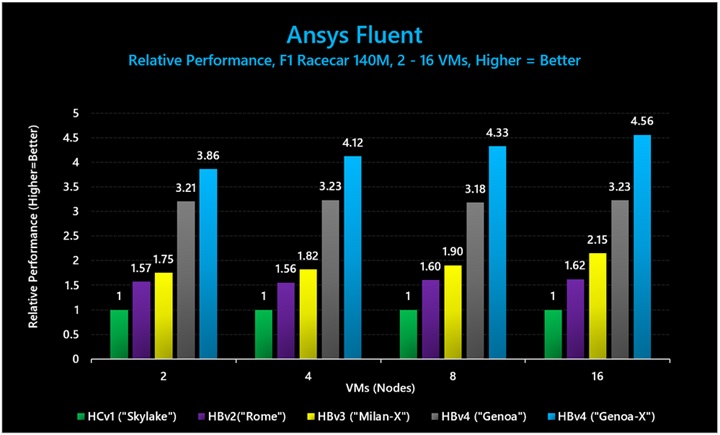
図 7: Ansys Fluent (F1 Racecar 140M) では、3D V-Cache ありの HBv4 VM のパフォーマンスは、3D V-Cache なしの HBv4/HX VM の 1.42 倍、HBv3 の 2.12 倍でした。
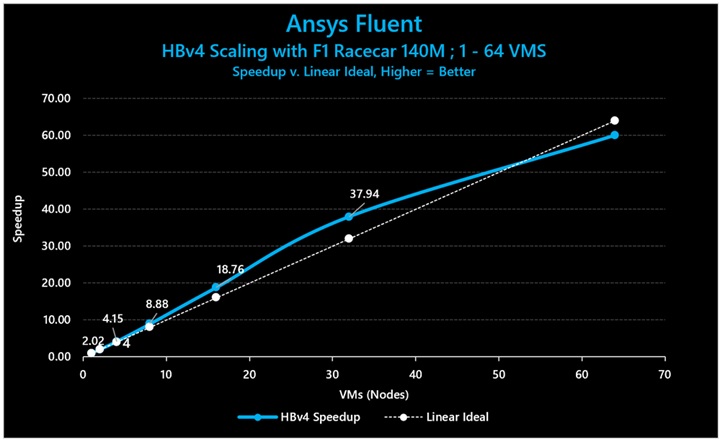
図 8: Ansys Fluent (F1 Racecar 140M) で HBv4 を 1 VM から 64 VM までスケールさせると、32 VM で最高 118.61% のスケーリング効率を示しました (32 VM で 37.9 倍の高速化)。
|
Nodes |
HBv4 (“Genoa-X”) |
HBv4 (“Genoa”) |
HBv3 (“Milan-X”) |
HBv2 (“Rome”) |
HCv1 (“Skylake”) |
|
1 |
192.07 |
159.7 |
84.27 |
76.1 |
N/A |
|
2 |
380.27 |
315.5 |
172.43 |
154.37 |
98.4 |
|
4 |
802.43 |
628.9 |
354.2 |
303.03 |
194.63 |
|
8 |
1690.8 |
1243.2 |
743.87 |
626.67 |
390.53 |
|
16 |
3539.83 |
2504.3 |
1670.4 |
1258.87 |
775.93 |
表 5: Ansys Fluent (F1 Racecar 140M) における絶対パフォーマンス (ソルバー評価の平均。数値が大きいほど優れている)。
Siemens Simcenter STAR-CCM+
注: すべての Siemens Simcenter STAR-CCM+ テストで、3D V-Cache ありの HBv4/HX のパフォーマンス データは Simcenter 18.04.005 を使用して収集し、3D V-Cache なしの HBv4 パフォーマンス データはバージョン 18.02.003 を使用して収集しました。どちらにも AlmaLinux 8.6 上の HPC-X 2.15 を使用しています。他の結果はすべて、CentOS 8.1 上の HPC-X 2.83 で Siemens Simcenter STAR-CCM+ 17.04.008 を使用して収集しました。なお、新しいバージョンのソフトウェアを使用することによるパフォーマンス上の既知のメリットはありません。Siemens、NVIDIA、AMD の各社での検証範囲の都合により、新旧のバージョンが使用されました。
なお、AMD ベースのシステムでは、Simcenter Star-CCM+ で xpmem を使用した場合、ページフォールトが大幅に増加して、パフォーマンスが下がります (約 10% のパフォーマンス低下)。これを回避するには、kmod-xpmem パッケージをアンインストールするか、xpmem モジュールをアンロードします。アプリケーションは、サポートされている UCX 提供の共有メモリ トランスポートにフォールバックします。他のユーザー作業は不要です。XPMEM のパッチは、UCX/NVIDIA OFED の 2023 年 7 月のリリースに含まれる予定です。
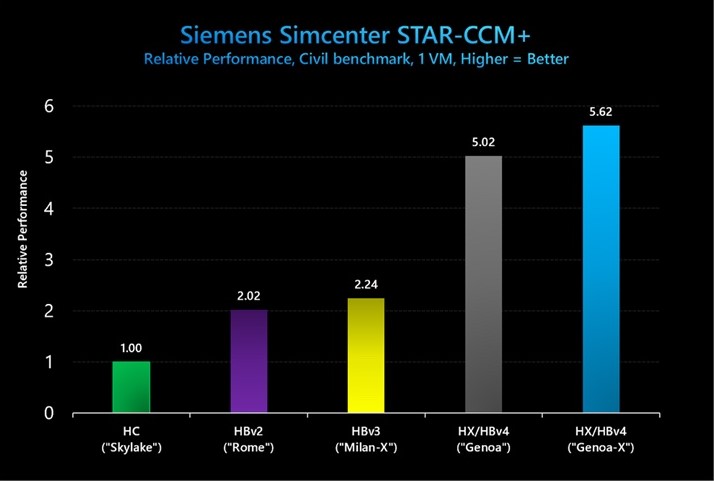
図 9: Siemens Simcenter STAR-CCM+ (Civil) では、3D V-Cache ありの HBv4/HX VM が 3D V-Cache なしの HBv4/HX に比べて 1.12 倍のパフォーマンス向上を示し、HBv3 シリーズに比べて 2.5 倍のパフォーマンス向上を示しました。
図 9 で示されているベンチマークの絶対パフォーマンス値 (経過時間) は以下のとおりです。
|
VM Tуре |
EIapsed Time (sec) |
|
4 year-old НРС server |
6.46 |
|
HBv2 |
3.2 |
|
HBv3 |
2.88 |
|
HBv4/HX (“Genoa“) |
1.29 |
|
HBv4/HX (“Genoa-X”) |
1.15 |
表 6: Siemens Simcenter STAR-CCM+ (Civil) における絶対パフォーマンス (経過時間。短いほど優れている)。
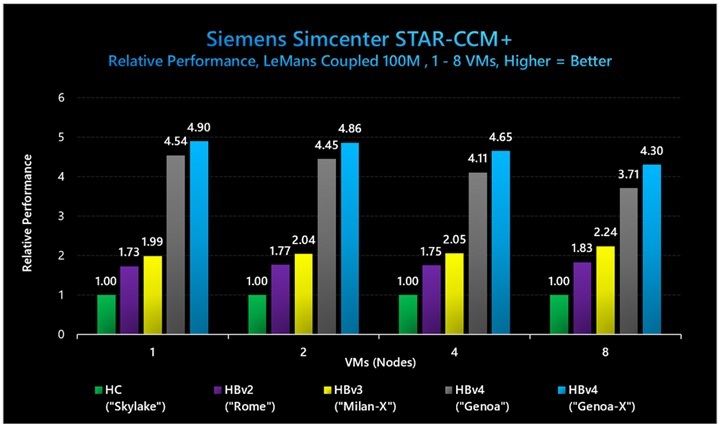
図 10: Siemens Simcenter STAR-CCM+ (LeMans Coupled 100M) では、3D V-Cache ありの HBv4 VM が 3D V-Cache なしの HBv4/HX に比べて 1.15 倍のパフォーマンスを示し、HBv3 に比べて 2.24 倍のパフォーマンス向上を示しました。
|
Number of nodes |
HBv4 (“Genoa-X”) |
HBv4 (“Genoa”) |
HBv3 (“Milan-X”) |
HBv2 (“Rome”) |
HC (“Skylake”) |
|
1 |
4.3 |
4.64 |
10.59 |
12.18 |
21.07 |
|
2 |
2.17 |
2.37 |
5.17 |
5.97 |
10.55 |
|
4 |
1.13 |
1.28 |
2.56 |
3 |
5.26 |
|
8 |
0.63 |
0.73 |
1.21 |
1.48 |
2.71 |
表 7: 各サイズの HBv4/HX VM での Siemens Simcenter STAR-CCM+ (LeMans Coupled 100M) における絶対パフォーマンス (経過時間。短いほど優れている)。
OpenFOAM
注: すべての OpenFOAM パフォーマンス テストには、OpenFOAM バージョン 2006、AlmaLinux 8.6、HPC-X MPI を使用しました。
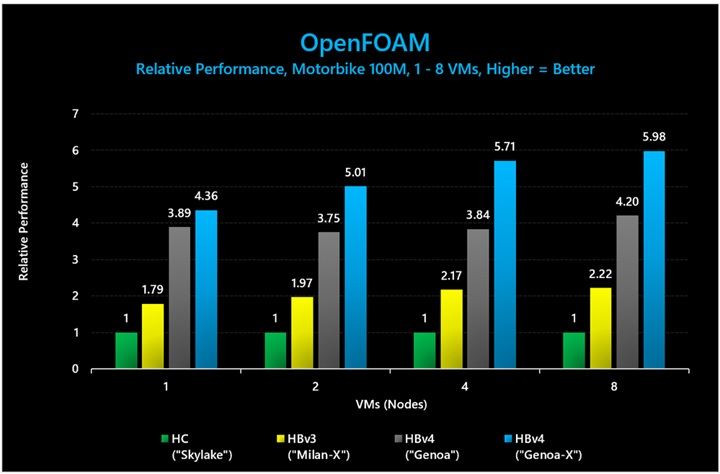
図 11: OpenFOAM (Motorbike 100 M) では、3D V-Cache ありの HBv4/HX VM が、3D V-Cache なしの HBv4/HX VM に比べて最大 1.49 倍のパフォーマンスを発揮し、HBv3 シリーズに比べて最大 2.7 倍のパフォーマンス向上がありました。
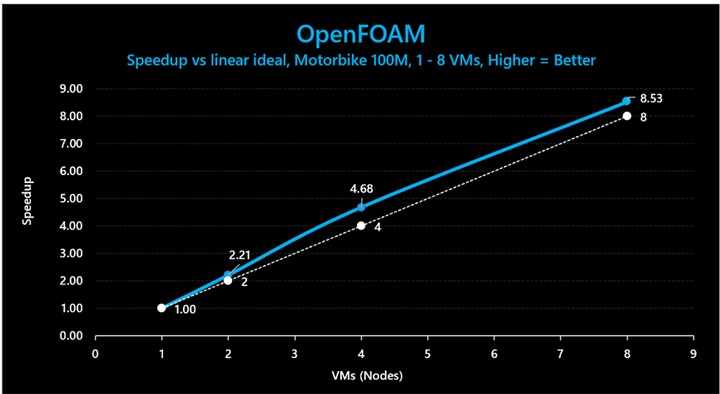
図 12: OpenFOAM (Motorbike 100M) では、3D V-Cache ありの HBv4/HX VM が、1 VM から 8 VM の間で最大 117% のスケーリング効率を示しました。
図 11 と図 12 で示されているベンチマークの絶対パフォーマンス値は以下のとおりです。
|
Number of Nodes |
HBv4 (“Genoa-X”) |
HBv4 (“Genoa”) |
HBv3 (“Milan-X”) |
HC (“Skylake”) |
|
1 |
1272.7 |
1423.53 |
3096.04 |
5542.9 |
|
2 |
558.6 |
745.23 |
1422.69 |
2796.83 |
|
4 |
245.19 |
365.15 |
644.94 |
1400.49 |
|
8 |
120.75 |
171.78 |
325.62 |
722.31 |
表 8: OpenFOAM (Motorbike セル数 100M) における絶対パフォーマンス (実行時間。短いほど優れている)。
Hexagon Cradle CFD
注: すべての Hexagon Cradle CFD のパフォーマンス テストでは、バージョン 2022 を AlmaLinux 8.6 で使用しました。
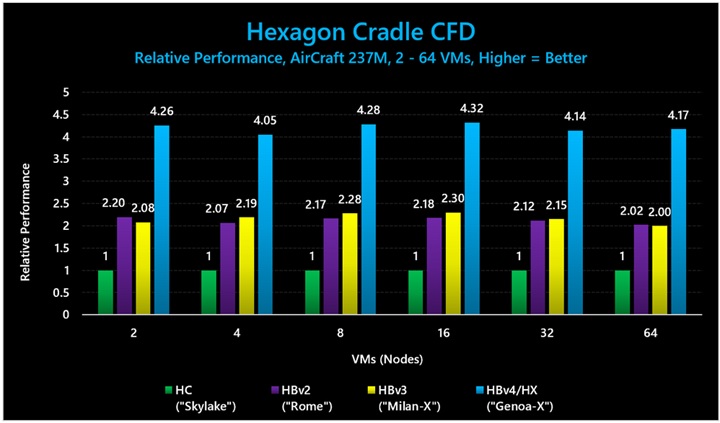
図 13: Hexagon Cradle CFD (AirCraft 237M) では、3D V-Cache ありの HBv4/HX VM が、HBv3 シリーズに比べて最大 2.1 倍のパフォーマンス向上を示しました。
図 15 と図 16 で示されているベンチマークの絶対パフォーマンス値 (時間ステップごとの平均時間) は以下のとおりです。
|
Nodes |
HBv4/HX (“Genoa-X”) |
HBv3 (“Milan-X”) |
HBv2 (“Rome”) |
HC (“Skylake”) |
|
2 |
790.029 |
1616.74 |
1529.883 |
3363.2 |
|
4 |
405.2395 |
749.7797 |
794.4137 |
1642.117 |
|
8 |
203.391 |
382.3693 |
401.8873 |
871.116 |
|
16 |
103.0343 |
193.719 |
204.304 |
445.3897 |
|
32 |
54.51093 |
104.7005 |
106.4333 |
225.6037 |
|
64 |
27.63247 |
57.7077 |
57.02497 |
115.2657 |
表 9: Hexagon Cradle CFD (AirCraft 237M) における絶対パフォーマンス (実行時間。短いほど優れている)。
有限要素解析 (FEA)
Altair RADIOSS
注: すべての Altair RADIOSS パフォーマンス テストには、RADIOSS バージョン 2021.1 を AlmaLinux 8.6 で使用しました。
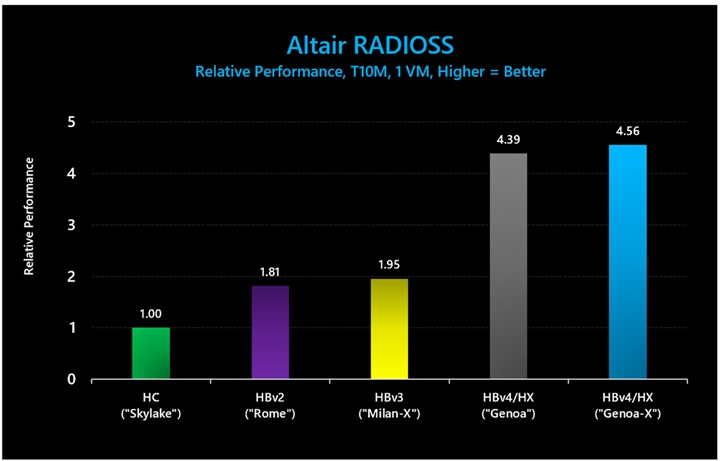
図 14: Altair Radioss (T10M) では、3D V-Cache ありの HBv4/HX VM が、3D V-Cache なしの HBv4/HX VM に比べて 1.03 倍のパフォーマンス向上を示し、HBv3 シリーズに比べて 2.34 倍のパフォーマンス向上を示しました。
|
VM Type |
Execution Time (sec) |
|
HC (“Skylake” ) |
3395 |
|
HBv2 (“Rome”) |
1873 |
|
HBv3 (“Milan-X”) |
1738 |
|
HBv4/HX (“Genoa”) |
773 |
|
HBv4/HX (“Genoa-X”) |
745 |
表 10: Altair Radioss (T10M) における絶対パフォーマンス (実行時間。短いほど優れている)。
MSC Nastran – バージョン 2022.3
注: すべての NASTRAN テスト パフォーマンス テストには、NASTRAN 2022.3 と AlmaLinux 8.6 を使用しました。
注: NASTRAN については、こうした大規模なメモリ ワークロードをサポートするように構築されている HX シリーズ VM でのみ SOL108 Medium のベンチマーク テストを行いました。HX シリーズのより大規模なメモリ領域 (HBv4 シリーズの 2 倍、HBv3 シリーズの 3 倍以上) を使用すると、ベンチマークは DRAM を最大限活用し、パフォーマンスを一層向上させます。これは、新しい 3D V-Cache 搭載の第 4 世代 EPYC プロセッサがもたらすパフォーマンス向上に、さらに上乗せするものとなります。したがって、下記のベンチマーク結果で “HBv4/HX” という表記を使用すると、パフォーマンス特性を正確に表現したことにならないため、代わりに “HX” のみを使用しています。
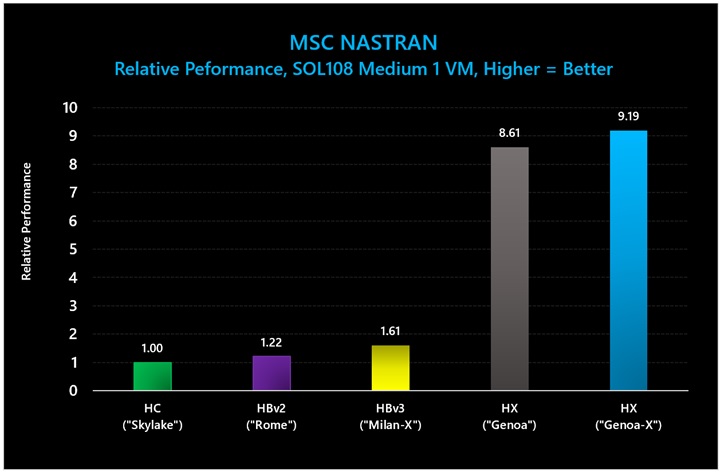
図 15: MSC NASTRAN (SOL108 Medium) では、3D V-Cache ありの HX シリーズ VM が、3D V-Cache なしの HX シリーズに比べて 1.07 倍のパフォーマンス向上を示し、HBv3 に比べて 5.7 倍のパフォーマンス向上を示しました。
図 14 で示されているベンチマークの絶対値は以下のとおりです。
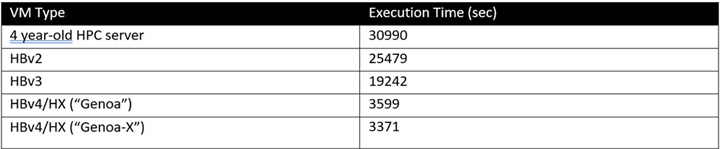
表 11: MSC NASTRAN における絶対パフォーマンス (実行時間。短いほど優れている)。
気象シミュレーション
WRF
注: HBv4/HX シリーズ (3D V-Cache ありとなしの両方) 上のすべての WRF パフォーマンス テストでは、WRF 4.2.2、HPC-X MPI 2.15、AlmaLinux 8.6 を使用しました。
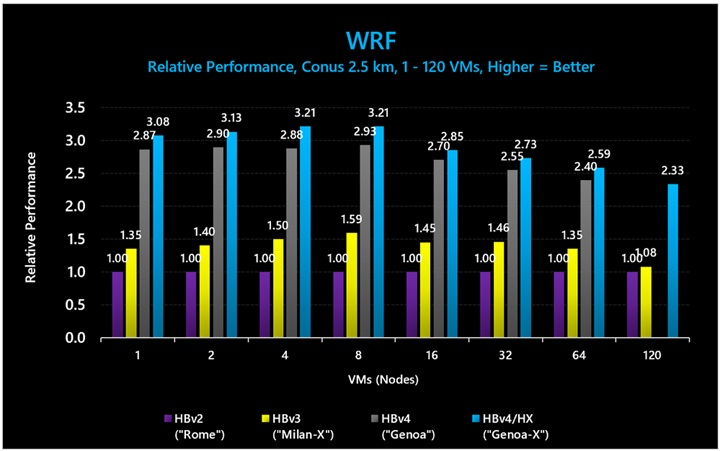
図 16: WRF (Conus 2.5km) では、3D V-Cache ありの HBv4/HX VM が、3D V-Cache なしの HBv4/HX VM に比べて最大 1.11 倍のパフォーマンス向上を示し、HBv3 シリーズに比べて最大 2.24 倍のパフォーマンス向上を示しました。
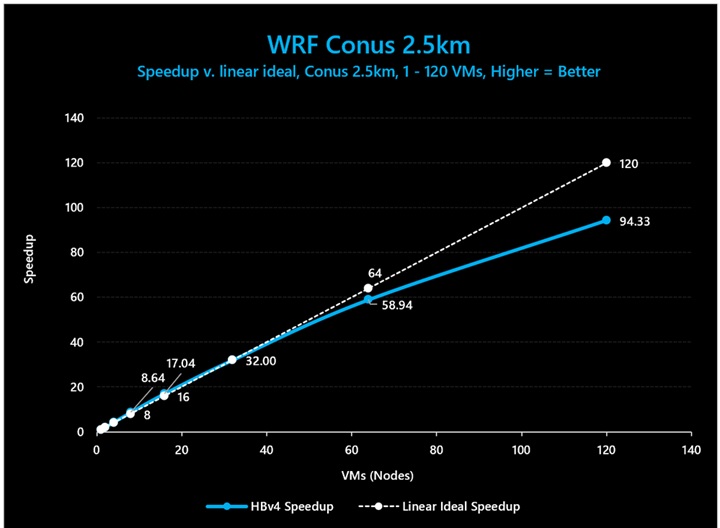
図 17: WRF (Conus 2.5km) では、HBv4 VM が 64 VM まで 92% のスケーリング効率を示しました。120 ノードでスケーリング効率が 79% に低下していることは、64 HBv4 VM を超えて超高効率でスケールするのに十分な大きさのモデル サイズになっていない可能性を示唆しています。
|
Nodes |
HBv4 (“Genoa-X”) |
HBv4 (“Genoa”) |
HBv3 (“Milan-X”) |
HBv2 (“Rome”) |
|
1 |
2.89 |
3.1 |
6.58 |
8.89 |
|
2 |
1.43 |
1.54 |
3.19 |
4.47 |
|
4 |
0.67 |
0.75 |
1.45 |
2.17 |
|
8 |
0.33 |
0.37 |
0.67 |
1.07 |
|
16 |
0.17 |
0.18 |
0.33 |
0.48 |
|
32 |
0.09 |
0.1 |
0.17 |
0.25 |
|
64 |
0.05 |
0.05 |
0.09 |
0.13 |
|
120 |
0.03 |
|
0.07 |
0.07 |
表 12: WRF (Conus 2.5km) における絶対パフォーマンス (時間/タイム ステップ。数値が小さいほど優れている)。
分子動力学
NAMD – バージョン 2.15
注: すべての NAMD パフォーマンス テストでは、NAMD バージョン 2.15 を AlmaLinux 8.6 と HPC-X 2.12 で使用しました。HBv4/HX シリーズと HC シリーズでは、Xeon Platinum 第 1 世代 “Skylake” と第 4 世代 EPYC “Genoa” および “Genoa-X” プロセッサの両方で、AVX512 機能を活用するために AVX512 タイル バイナリを使用しました。なお、AMD システムでは、xpmem を使用した場合、ページフォールトが大幅に増加して、パフォーマンスが下がります (約 10% のパフォーマンス低下)。これを回避するには、kmod-xpmem パッケージをアンインストールするか、xpmem モジュールをアンロードします。アプリケーションは、サポートされている UCX 提供の共有メモリ トランスポートにフォールバックします。他のユーザー作業は不要です。XPMEM のパッチは、UCX/NVIDIA OFED の 2023 年 7 月のリリースに含まれる予定です。
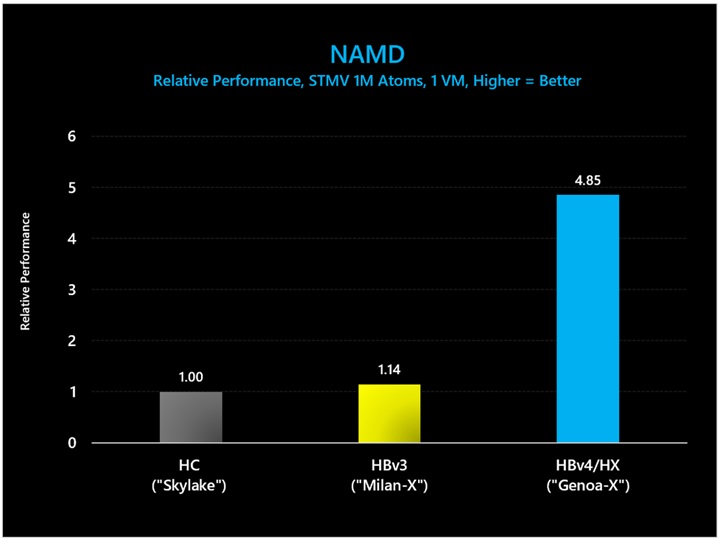
図 18: NAMD (STMV 原子数 100 万) では、3D V-Cache ありの HBv4/HX VM が HBv3 シリーズに比べて 4.25 倍のパフォーマンス向上を示しました。
図 17 で示されているベンチマークの絶対パフォーマンス値 (ナノ秒/日) は以下のとおりです。
|
VM Type |
Nanoseconds/Day |
|
HC (“Skylake”) |
1.13 |
|
HBv3 (“Milan-X”) |
1.29 |
|
HBv4/HX (“Genoa-X”) |
5.46 |
表 13: NAMD (STMV 原子数 100 万) における絶対パフォーマンス (ナノ秒/日。数値が大きいほど優れている)。
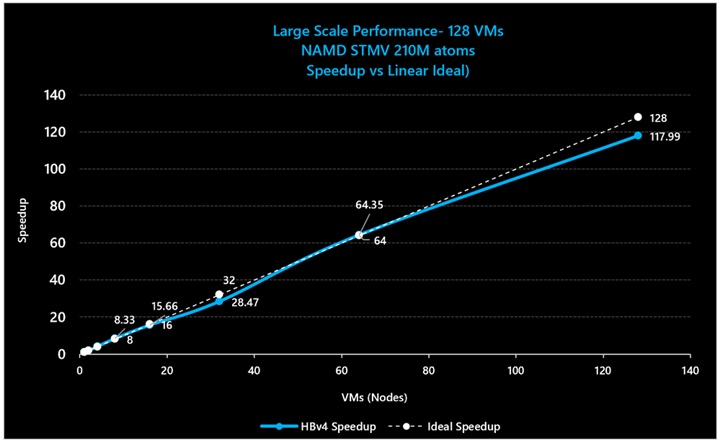
図 19: NAMD (STMV 原子数 2.1 億) における 3D V-Cache ありの HBv4/HX VM のスケーリング効率 (64 VM で 100% のスケーリング効率、128 VM で 92% のスケーリング効率)。
レンダリング
Chaos V-Ray
バージョン 5.02.00。すべての HBv4/HX VM 上のテストには AlmaLinux 8.6 を使用し、すべての HBv3、HBv2、HC 上のテストには CentOS 7.9 を使用しました。なお、新しいバージョンのソフトウェアを使用することによるパフォーマンス上の既知のメリットはありません。AMD での検証範囲の都合により、新旧のバージョンが使用されました。
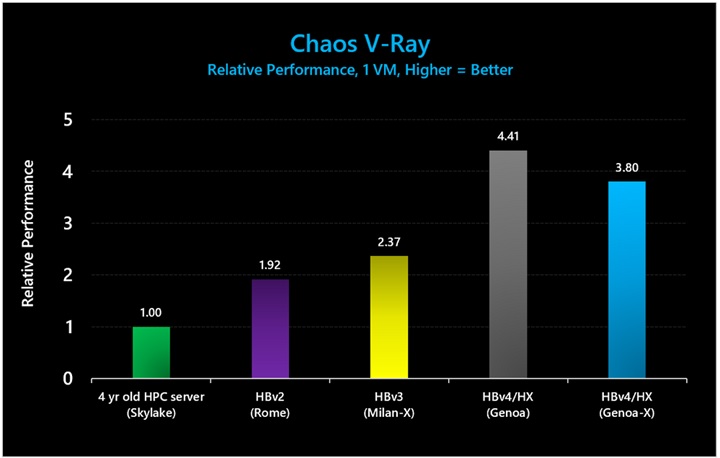
図 20: Chaos V-Ray 5 では、3D V-Cache ありの HBv4/HX VM が、3D V-Cache なしの HBv4/HX シリーズ VM よりも 14% 低いパフォーマンスという結果となり、HBv3 シリーズと比較した場合には 1.6 倍のパフォーマンス向上がありました。3D V-Cache 搭載の第 4 世代 EPYC プロセッサのパフォーマンスが 3D V-Cache 非搭載よりも低いのは意外ではありません。このワークロードは計算能力に大きく依存するため、標準の第 4 世代 EPYC プロセッサの方がコアに割り当てられる電力が大きいことが有利に働いています。
図 20 で示されているベンチマークの絶対パフォーマンス値 (レンダリングされたフレーム数) は以下のとおりです。
|
VM Type |
Frames Rendered |
|
HC (“Skylake”) |
30942 |
|
HBv2 (“Rome”) |
59354 |
|
HBv3 (“Milan-X”) |
73198 |
|
HBv4/HX (“Genoa”) |
136321 |
|
HBv4/HX (“Genoa-X) |
117695 |
表 14: Chaos V-Ray 5 における絶対パフォーマンス (レンダリングされたフレーム数。多いほど優れている)。
化学
CP2K
バージョン 9.1。HBv4/HX VM 上のすべてのテストには AlmaLinux 8.7 と HPC-X 2.15 を使用し、HBv3 VM 上のすべてのテストには CentOS 8.1 と HPC-X 2.8.3 を使用しました。なお、新しいバージョンのソフトウェアを使用することによるパフォーマンス上の既知のメリットはありません。NVIDIA と AMD の各社での検証範囲の都合により、新旧のバージョンが使用されました。
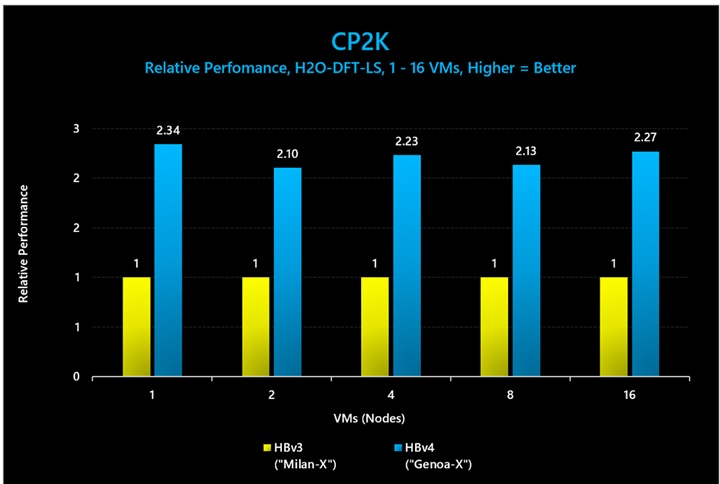
図 21: CP2K (H2O-DFT-LS) では、3D V-Cache ありの HBv4/HX VM が HBv3 シリーズに比べて最大 2.34 倍のパフォーマンス向上を示しました。
図 21 で示されているベンチマークの絶対パフォーマンス値 (平均実行時間) は以下のとおりです。
|
Nodes |
HBv4 (“Genoa-X”) |
HBv3 (“Milan-X”) |
|
1 |
1193.25 |
2795.55 |
|
2 |
633.52 |
1333.49 |
|
4 |
325.37 |
726.13 |
|
8 |
175.02 |
373.26 |
|
16 |
95.46 |
216.67 |
表 15: CP2K (H2O-DFT-LS) における絶対パフォーマンス (実行時間。短いほど優れている)。
