
機械翻訳
機械翻訳とは何ですか?
機械翻訳システムは、機械学習技術を使用して、サポートされている言語から大量のテキストを翻訳するアプリケーションまたはオンラインサービスです。このサービスは、"ソース" テキストを1つの言語から別の "ターゲット" 言語に変換します。
機械翻訳技術とそれを使用するインターフェイスの背後にある概念は比較的簡単ですが、その背後にある科学と技術は非常に複雑であり、一緒にいくつかの最先端の技術、特に、深い学習をもたらす (人工知能)、ビッグデータ、言語学、クラウドコンピューティング、および web api。
初期の2010s、新しい人工知能技術、ディープニューラルネットワーク (別名ディープラーニング) 以来、音声認識の技術は、Microsoft の翻訳チームは、音声認識を組み合わせることができる品質レベルに到達することができました新しい音声翻訳技術を起動するためのコアテキスト翻訳技術。
歴史的には、業界で使用される一次機械学習技術は統計機械翻訳 (SMT) でした。SMT は、いくつかの単語の文脈を与えられた単語のための最良の翻訳を推定するために高度な統計解析を使用します。SMT は、マイクロソフトを含むすべての主要な翻訳サービスプロバイダーによって2000年代半ばから使用されています。
神経機械翻訳 (NMT) の出現は翻訳技術の根本的な転位を引き起こし、大いにより高い質の翻訳をもたらした。この翻訳技術は、ユーザーと開発者のための展開を開始 2016の後半部分.
SMT と NMT の両方の翻訳技術には、共通する2つの要素があります。
- どちらも、システムを訓練するために事前に人間が翻訳されたコンテンツ (最大数百万の翻訳文) を大量に必要とします。
- どちらもバイリンガル辞書として機能し、翻訳の可能性のリストに基づいて単語を翻訳するが、文で使用されている単語の文脈に基づいて翻訳する。
翻訳者とは?
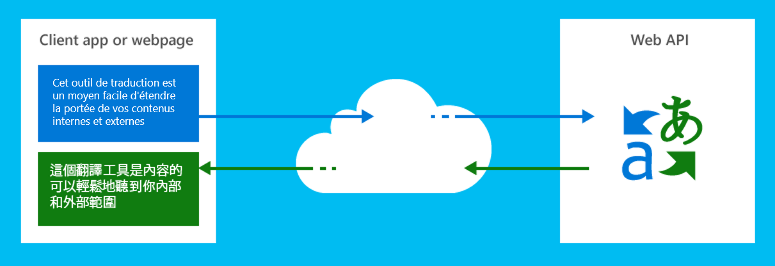
翻訳者とスピーチサービス、の一部 認知サービス api のコレクションは、マイクロソフトの機械翻訳サービスです。
テキストの翻訳
Translatorは2007年からMicrosoftグループで使用されており、2011年からは顧客向けのAPIとして提供されています。TranslatorはMicrosoft社内で広く使われている。製品のローカリゼーション、サポート、オンラインコミュニケーションの各チームに組み込まれている。この同じサービスは、以下のような馴染みのあるMicrosoft製品からも、追加費用なしでアクセスできます。 Bing, Cortana, マイクロソフトのエッジ, オフィス, sharepoint, Skypeとしています。 yammer.
翻訳者は、任意のハードウェアプラットフォーム上のWebまたはクライアントアプリケーションで使用することができ、言語翻訳および言語検出、音声へのテキスト、または辞書などの他の言語関連の操作を実行するために、任意のオペレーティングシステムを持つことができます。
業界標準の REST テクノロジを活用することで、開発者はターゲット言語を示すパラメータを使用して、ソーステキスト (または音声翻訳用の音声) をサービスに送信し、サービスは使用するクライアントまたは web アプリの翻訳済みテキストを返送します。
Translatorサービスは、マイクロソフトのデータセンターでホストされているAzureサービスであり、他のマイクロソフトのクラウドサービスと同様に、セキュリティ、スケーラビリティ、信頼性、ノンストップの可用性の恩恵を受けることができます。
音声翻訳
Translatorの音声翻訳技術は、2014年末に「Skype Translator」を皮切りに提供を開始し、2016年初めからお客様向けのオープンAPIとして提供しています。Microsoft Translatorのライブ機能、Skype、Skypeミーティングブロードキャスト、AndroidやiOSのMicrosoft Translatorアプリに組み込まれています。
音声翻訳は、音声認識、音声翻訳、音声合成 (テキスト読み上げ) のための完全にカスタマイズ可能なサービスのエンドツーエンドのセットである Microsoft 音声を通じて利用できるようになりました。
テキスト翻訳はどのように機能しますか?
テキストの翻訳に使用される2つの主要な技術があります: レガシー1、統計機械翻訳 (SMT)、および新しい世代1、神経機械翻訳 (NMT)。
統計機械翻訳
統計的機械翻訳(SMT)のTranslatorの実装は、Microsoftでの10年以上に及ぶ自然言語研究の上に構築されています。現代の翻訳システムは、言語間を翻訳するために手作りのルールを書くのではなく、既存の人間の翻訳から言語間のテキストの変換を学習し、応用統計と機械学習の最近の進歩を活用する問題として翻訳にアプローチしています。
いわゆる「並列コーパス」と呼ばれるものは、現代のロゼッタストーンのようなもので、多くの言語ペアや領域の文脈での単語、フレーズ、慣用句の翻訳を提供しています。統計的なモデリング技術と効率的なアルゴリズムは、コンピュータが解読(訓練データのソースとターゲット言語の間の対応を検出)と解読(新しい入力文の最良の翻訳を見つける)の問題に対処するのを助けます。翻訳者は、統計的手法と言語情報を組み合わせて、より一般化し、より理解しやすい翻訳につながるモデルを生成します。
辞書や文法規則に依存しないこのアプローチのために、それは1つの単語の翻訳を実行しようとする対特定の単語の周りのコンテキストを使用することができますフレーズの最高の翻訳を提供します。単一の単語の翻訳のために、二か国語の辞書は開発され、通じてアクセス可能である www.bing.com/translator.
神経機械翻訳
翻訳の継続的な改善は重要です。しかし、SMT技術では2010年代半ば以降、パフォーマンスの向上は停滞しています。MicrosoftのAIスーパーコンピュータ、特にMicrosoft Cognitive Toolkitのスケールとパワーを活用することで、Translatorは現在、ニューラルネットワーク(LSTM) の翻訳品質向上の新しい10年を可能にするベースの翻訳。
これらのニューラルネットワークモデルは、Azure上のSpeechサービスを通じて、またテキストAPIを通じて、'generalnn'カテゴリIDを使用して、すべての音声言語で利用可能です。
ニューラルネットワークの翻訳は、基本的には、従来の SMT のものと比較して実行される方法が異なります。
次のアニメーションは、ニューラルネットワークの翻訳が文を翻訳するために通過するさまざまなステップを示しています。このアプローチのために、翻訳は文脈に完全な文を、唯一のいくつかの単語は、SMT 技術を使用して、より多くの流体と人間の翻訳を探して変換を生成するウィンドウをスライディングにかかります。
ニューラルネットワークのトレーニングに基づいて、各単語は、特定の言語ペア (英語と中国語など) 内の固有の特性を表す500次元ベクトル (a) に沿って符号化されます。トレーニングに使用される言語のペアに基づいて、ニューラルネットワークは、これらの次元が何であるべきかを自己定義します。彼らは、ジェンダーのような単純な概念をエンコードすることができます (女性、男性、中立的)、礼儀正しさレベル (俗語、カジュアル、書かれた、フォーマルなど)、単語の種類 (動詞、名詞など) だけでなく、トレーニングデータから派生した他の非自明の特性。
ニューラルネットワークの翻訳の手順は、次のとおりです。
- 各単語、またはより具体的にそれを表す500次元ベクトルは、文中の他の単語の文脈の中で単語を表す1000次元ベクトル (b) でそれをエンコードする "ニューロン" の最初の層を通過します。
- すべての単語がこれらの1000次元ベクトルに1回符号化されたら、プロセスは複数回繰り返される、各層は完全な文の文脈内の単語のこの1000次元の表現のよりよい微調整を可能にする (SMT に反対のみを考慮することができます技術3〜5ワードウィンドウ)
- 最終的な出力行列は、次にソース文からの単語を定義するために、この最終的な出力行列と以前に翻訳された単語の出力の両方を使用する注意層 (すなわち、ソフトウェアアルゴリズム) によって使用されます。また、これらの計算を使用して、ターゲット言語で不要な単語を削除する可能性があります。
- デコーダ (翻訳) レイヤは、選択された単語 (または、完全な文のコンテキスト内でこの単語を表す1000次元のベクトル) を、その最も適した対象言語と等価に変換します。この最後の層 (c) の出力は、ソース文から次の単語が翻訳されるべきであることを計算するために注意層に戻って供給されます。

アニメーションに示されている例では、コンテキスト対応の1000ディメンションモデル "、"は、その名詞を符号化する (家) はフランス語で女性らしい言葉 (ラメゾン).これは、適切な翻訳を可能にする "、「する」La」ではなく「ル"(単数、男性) または"レ"(複数) は、デコーダ (翻訳) 層に達すると。
注意アルゴリズムはまた、以前に翻訳された単語 (この場合は ") に基づいて計算します。、") は、次の単語を翻訳する必要があります件名 ("家") ではなく、形容詞 ("青").システムは、英語とフランス語は、文の中でこれらの単語の順序を反転することを学んだので、これを達成することができます。それはまた、形容詞がされている場合は、計算しているだろう "大きな"色の代わりに、それはそれらを反転してはならないこと ("大家"= >"ラ・グランデ・メゾン").
このアプローチのおかげで、最終的な出力は、ほとんどの場合、より流暢で、SMT ベースの翻訳よりも人間の翻訳に近いこれまでされている可能性があります。
音声翻訳はどのように機能しますか?
Translatorは音声の翻訳も可能です。この技術はTranslatorのライブ機能で公開されています(http://translate.it), 翻訳アプリ, skype の翻訳者はまた、最初は skype の翻訳機能を介してのみ利用可能にし、iOS と Android 上のマイクロソフトの翻訳アプリで, この機能は、オープンの最新バージョンを使用して開発者に利用できるようになりましたAzure ポータルで使用できる REST ベースの API。
それは、既存の技術のレンガから音声翻訳技術を構築するために一目でまっすぐ進むプロセスのように見えるかもしれませんが、それは単に既存の "伝統的な" 人間と機械の音声認識を差し込むよりもはるかに多くの作業を必要と既存のテキスト翻訳1にエンジン。
"ソース" 音声をある言語から別の "ターゲット" 言語に適切に変換するには、システムは4段階のプロセスを実行します。
- 音声認識は、テキストにオーディオを変換する
- TrueText: 翻訳に適したテキストを正規化するマイクロソフトのテクノロジ
- 上記のテキスト翻訳エンジンを通じて翻訳が、実際の生活のために特別に開発された翻訳モデルで会話を話す
- テキストを音声に、必要に応じて、翻訳されたオーディオを生成します。

自動音声認識 (ASR)
自動音声認識 (ASR) は、入力音声の数千時間を分析するために訓練を受けたニューラルネットワーク (NN) システムを使用して実行されます。このモデルは、人間と人間の相互作用ではなく、人と機械のコマンドは、通常の会話のために最適化された音声認識を生成する訓練を受けています。これを実現するためには、従来のヒューマン・ツー・マシンの ASRs よりもはるかに多くのデータが必要になり、より大きな DNN が得られます。
詳細情報 テキストサービスへのマイクロソフトのスピーチ.
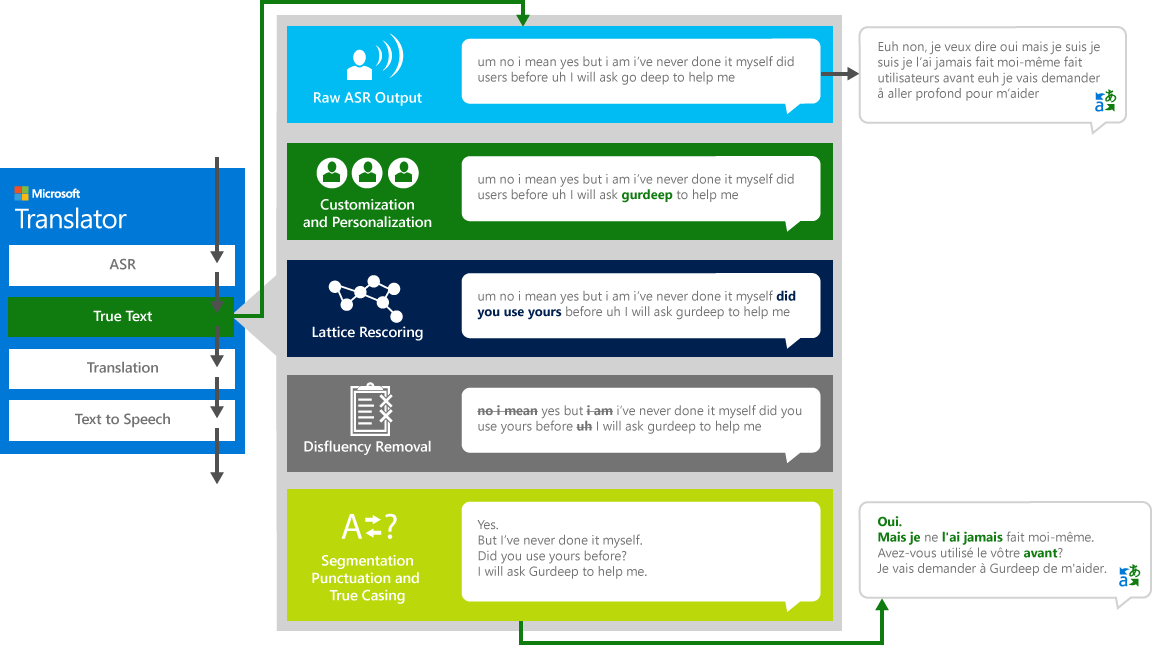
TrueText
人間が他の人間と会話するので、私達は私達が頻繁に私達が考えるように完全に、はっきりまたはきちんと話さない。TrueText テクノロジを使用すると、リテラルテキストは、"um" s、"ah" s "、" s "、" s、吃音、繰り返し "のように、音声言いよどみ (フィラーの単語) を削除することにより、ユーザーの意図をより厳密に反映するように変換されます。テキストは、改行、適切な句読点、および大文字小文字を追加することによって、より読みやすく翻訳できます。これらの結果を達成するために、我々は TrueText を作成するために翻訳者から開発された、言語技術の仕事の数十年を使用していました。次の図は、実際の例を通じて、さまざまな変換 TrueText がこのリテラルテキストを正規化するために動作することを示しています。
翻訳
テキストは、次のいずれかに変換されます。 げんごほうげん Translatorでサポートされています。
翻訳は、音声翻訳 API を使用して (開発者として)、または音声翻訳アプリやサービスでは、すべての音声入力をサポートする言語の最新のニューラルネットワークベースの翻訳を搭載しています ( ここは 完全なリストのために)。これらのモデルは、現在の主に書かれたテキストの訓練を受けた翻訳モデルを拡大することによって構築された, より多くの話し言葉のコーパスと翻訳の話し言葉の会話の種類のためのより良いモデルを構築する.これらのモデルは、 "音声" 標準カテゴリ 伝統的なテキスト翻訳 API の。
ニューラル翻訳でサポートされていない言語では、従来の SMT 変換が実行されます。
音声へのテキスト
ターゲット言語が18のサポートされている音声合成のいずれかである場合 言語、ユースケースは音声出力を必要とし、テキストは音声合成を使用して音声出力に変換されます。このステージは、音声からテキストへの変換のシナリオでは省略されています。
詳細情報 音声サービスへのマイクロソフトのテキスト.
研究
マイクロソフトの翻訳チームから最新の研究論文をご覧ください。



