
Machine vertaling
Wat is machine translation?
Machine translation systemen zijn toepassingen of online diensten die gebruik maken van machine-learning technologieën om grote hoeveelheden tekst te vertalen van en naar een van hun ondersteunde talen. De dienst vertaalt een "bron" tekst van de ene taal naar een andere "target" language.
Hoewel de concepten achter machine translation technologie en de interfaces om het te gebruiken zijn relatief eenvoudig, de wetenschap en technologieën achter het zijn uiterst complex en het samenbrengen van verschillende geavanceerde technologieën, in het bijzonder, Deep Learning ( kunstmatige intelligentie), grote data, taalkunde, Cloud Computing, en Web api's.
Sinds het begin van 2010, een nieuwe kunstmatige intelligentie technologie, diepe neurale netwerken (aka Deep learning), heeft de technologie van spraakherkenning toegestaan om een kwaliteitsniveau dat het Microsoft Translator team toegestaan om spraakherkenning te combineren met zijn te bereiken kerntekst vertaaltechnologie om een nieuwe toespraak vertaaltechnologie te lanceren.
Historisch, was de primaire machine het leren techniek die in de industrie wordt gebruikt statistische machine vertaling (SMT). SMT gebruikt geavanceerde statistische analyse om de best mogelijke vertalingen voor een woord te schatten, gezien de context van een paar woorden. SMT is sinds het midden van de jaren 2000 door alle belangrijke Vertaal dienstverleners, met inbegrip van Microsoft gebruikt.
De komst van neurale machine translation (NMT) veroorzaakte een radicale verschuiving in de vertaaltechnologie, resulterend in veel hogere kwaliteit vertalingen. Deze vertaaltechnologie begon met de implementatie voor gebruikers en ontwikkel- laatste deel van 2016.
Zowel SMT en NMT vertaling technologieën hebben twee elementen gemeen:
- Beide vereisen grote hoeveelheden pre-menselijke vertaalde inhoud (tot miljoenen vertaalde zinnen) om de systemen op te leiden.
- Noch fungeren als tweetalige woordenboeken, het vertalen van woorden op basis van een lijst van mogelijke vertalingen, maar vertalen op basis van de context van het woord dat wordt gebruikt in een zin.
Wat is Translator?
Vertaler- en spraakdiensten, onderdeel van de Cognitieve diensten verzameling van api's, zijn machine translation services van Microsoft.
Vertalen van tekst
Translator wordt sinds 2007 gebruikt door Microsoft-groepen en is sinds 2011 beschikbaar als API voor klanten. Translator wordt veel gebruikt binnen Microsoft. Het is opgenomen in productlokalisatie-, ondersteunings- en online communicatieteams. Dezelfde service is ook zonder extra kosten toegankelijk vanuit bekende Microsoft-producten zoals Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypeen Yammer.
Vertaler kan worden gebruikt in web- of clienttoepassingen op elk hardwareplatform en met elk besturingssysteem om taalvertaling en andere taalgerelateerde bewerkingen uit te voeren, zoals taaldetectie, tekst naar spraak of woordenboek.
Leveraging industrie standaard rest technologie, de ontwikkelaar verzendt brontekst (of audio voor toespraak vertaling) aan de dienst met een parameter die de doeltaal aangeeft, en de dienst verzendt de vertaalde tekst voor de cliënt of web app terug om te gebruiken.
De Translator-service is een Azure-service die wordt gehost in Microsoft-datacenters en profiteert van de beveiliging, schaalbaarheid, betrouwbaarheid en non-stop beschikbaarheid die andere Microsoft-cloudservices ook ontvangen.
Spraak vertaling
Translator spraakvertalingstechnologie werd eind 2014 gelanceerd, te beginnen met Skype Translator, en is sinds begin 2016 beschikbaar als open API voor klanten. Het is geïntegreerd in de Live-functie van Microsoft Translator, Skype, Skype-vergaderingsuitzending en de Microsoft Translator-apps voor Android en iOS.
De vertaling van de toespraak is nu beschikbaar door de toespraak van Microsoft, een eind-aan-eindreeks volledig klantgerichte diensten voor toespraakerkenning, toespraak vertaling, en toespraaksynthese (tekst-aan-toespraak).
Hoe werkt tekstvertaling?
Er zijn twee belangrijke technologieën die voor tekstvertaling worden gebruikt: erfenis één, statistische machine vertaling (SMT), en nieuwere generatie, neurale machine vertaling (NMT).
Statistische machine vertaling
Translator's implementatie van Statistical Machine Translation (SMT) is gebaseerd op meer dan tien jaar natuurlijk taalonderzoek bij Microsoft. In plaats van handgemaakte regels te schrijven om te vertalen tussen talen, benaderen moderne vertaalsystemen vertaling als een probleem van het leren van de transformatie van tekst tussen talen van bestaande menselijke vertalingen en het benutten van recente ontwikkelingen in toegepaste statistieken en machine learning.
De zogenaamde "parallelle corpora" fungeren als een moderne Steen Rosetta in massieve proporties, die woord, uitdrukking, en idiomatische vertalingen in context voor vele taalparen en domeinen verstrekt. Statistische modelleringstechnieken en efficiënte algoritmen helpen de computer het probleem van het ontcijferen (het detecteren van de correspondentie tussen bron- en doeltaal in de trainingsgegevens) en het decoderen (het vinden van de beste vertaling van een nieuwe invoerzin) aanpakken. Translator verenigt de kracht van statistische methoden met taalkundige informatie om modellen te produceren die beter generaliseren en leiden tot begrijpelijkere vertalingen.
Wegens deze benadering, die zich niet op woordenboeken of grammaticale regels baseert, verstrekt het de beste vertalingen van uitdrukkingen waar het de context rond een bepaald woord kan gebruiken versus het proberen om enige woord vertalingen uit te voeren. Voor losse vertalingen werd het tweetalige woordenboek ontwikkeld en is het toegankelijk via www.Bing.com/Translator.
Neurale machine vertaling
Continue verbeteringen aan de vertaling zijn belangrijk. Sinds het midden van de jaren 2010 zijn de prestatieverbeteringen echter gestagneerd met de SMT-technologie. Door gebruik te maken van de schaal en kracht van Microsoft's AI supercomputer, met name de Microsoft Cognitive Toolkit, biedt Translator nu een neuraal netwerk (LSTM) gebaseerde vertaling die een nieuw decennium van Vertaal kwaliteitsverbetering toelaat.
Deze neurale netwerkmodellen zijn beschikbaar voor alle spraaktalen via Spraakservice op Azure en via de tekst-API met behulp van de categorie-ID 'generalnn'.
Neurale netwerk vertalingen fundamenteel verschillen in hoe ze worden uitgevoerd in vergelijking met de traditionele SMT Ones.
De volgende animatie toont de verschillende stappen neurale netwerk vertalingen gaan door naar een zin te vertalen. Wegens deze benadering, zal de vertaling in context de volledige zin, versus slechts een paar woorden glijdend venster nemen dat de technologie SMT gebruikt en meer vloeistof en mens-vertaalde het kijken vertalingen zal produceren.
Gebaseerd op de neurale-netwerk opleiding, is elk woord gecodeerd langs een 500-afmetingen vector (a) die zijn unieke kenmerken binnen een bepaald taalpaar (bijv. Engels en Chinees). Gebaseerd op de taalparen gebruikt voor de opleiding, zal het neurale netwerk zelf te definiëren wat deze dimensies moeten worden. Ze kunnen coderen eenvoudige concepten zoals gender (vrouwelijk, mannelijk, neutraal), beleefdheid niveau (slang, Casual, geschreven, formeel, enz.), het type woord (werkwoord, zelfstandige naam, enz.), maar ook alle andere niet-duidelijke kenmerken zoals afgeleid van de opleiding gegevens.
De stappen neurale netwerk vertalingen gaan door zijn de volgende:
- Elk woord, of meer specifiek de 500-dimensie vector die het vertegenwoordigt, gaat door een eerste laag van "neuronen" dat zal coderen in een 1000-Dimension vector (b) die het woord in de context van de andere woorden in de zin.
- Zodra alle woorden zijn gecodeerd een keer in deze 1000-Dimension vectoren, het proces wordt meerdere malen herhaald, elke laag waardoor een betere fine-tuning van deze 1000-dimensie vertegenwoordiging van het woord in de context van de volledige zin (in tegenstelling tot SMT technologie die alleen rekening kan houden met een 3 tot 5 woorden venster)
- De uiteindelijke output matrix wordt vervolgens gebruikt door de aandacht laag (dwz een software-algoritme) die zowel deze uiteindelijke output matrix en de output van de eerder vertaalde woorden te definiëren welk woord, uit de bron zin, moet worden vertaald volgende. Het zal ook gebruik maken van deze berekeningen om mogelijk te laten vallen onnodige woorden in de doeltaal.
- De decoder (Translation) laag, vertaalt het geselecteerde woord (of meer specifiek de 1000-dimensie vector die dit woord in de context van de volledige zin) in de meest geschikte doeltaal equivalent. De output van deze laatste laag (c) wordt dan gevoed terug in de aandacht laag om te berekenen welke volgende woord van de bron zin zou moeten worden vertaald.

In het voorbeeld dat in de animatie wordt afgebeeld, is het context bewuste 1000-dimensie model van "De"zal coderen dat het zelfstandig naamwoord (Huis) is een vrouwelijk woord in het Frans (La Maison). Hierdoor kan de juiste vertaling voor "De"te zijn"La"en niet"Le"(enkelvoud, mannelijk) of"Les"(meervoud) zodra het de decoder (Translation) laag bereikt.
De aandacht algoritme zal ook berekenen, gebaseerd op het woord (en) eerder vertaald (in dit geval "De"), dat het volgende te vertalen woord het onderwerp moet zijn ("Huis") en geen bijvoeglijk naamwoord ("Blauwe"). In kan dit bereiken omdat het systeem leerde dat Engels en Frans de volgorde van deze woorden in zinnen omkeren. Het zou ook hebben berekend dat als het bijvoeglijk naamwoord zou zijn "Grote"in plaats van een kleur, dat het niet moet omkeren hen ("het grote huis"= >"La Grande Maison").
Dankzij deze aanpak, de uiteindelijke output is, in de meeste gevallen, meer vloeiend en dichter bij een menselijke vertaling dan een SMT-gebaseerde vertaling ooit had kunnen zijn geweest.
Hoe werkt spraak vertaling?
Vertaler is ook in staat om spraak te vertalen. Deze technologie wordt blootgesteld in de Functie Live-functie Translator (http://translate.it), de vertaler apps, Skype Translator en is ook in eerste instantie alleen beschikbaar gesteld via de Skype Translator-functie en in de Microsoft Translator apps op Ios en Android, deze functionaliteit is nu beschikbaar voor ontwikkel software met de nieuwste versie van de open REST-based API beschikbaar op de Azure Portal.
Hoewel het lijkt misschien een rechttoe rechtaan proces op een eerste gezicht om een toespraak vertaling technologie te bouwen van de bestaande technologie bakstenen, het vereist veel meer werk dan alleen het aansluiten van een bestaande "traditionele" mens-to-machine spraakherkenning motor aan bestaande tekstvertaling één.
Om goed te vertalen de "bron" toespraak van de ene taal naar een andere "target" taal, het systeem gaat door een vier-stappen proces.
- Spraakherkenning, om audio in tekst om te zetten
- TrueText: een Microsoft-technologie die de tekst normaliseert om het geschikter te maken voor vertaling
- Vertaling via de tekstvertaling engine hierboven beschreven, maar op de vertaling modellen speciaal ontwikkeld voor het echte leven gesproken gesprekken
- Tekst-naar-spraak, indien nodig, om de vertaalde audio te produceren.

Automatische spraakherkenning (ASR)
Automatische spraakherkenning (ASR) wordt uitgevoerd met behulp van een neuraal netwerk (nn) systeem getraind op het analyseren van duizenden uren van inkomende audio-spraak. Dit model is getraind op mens-op-mens interacties in plaats van mens-naar-machine commando's, het produceren van spraakherkenning die is geoptimaliseerd voor normale gesprekken. Om dit te bereiken, is veel meer gegevens nodig, evenals een grotere DNN dan de traditionele mens-to-machine ASRs.
Meer informatie over De toespraak van Microsoft aan de diensten van de tekst.
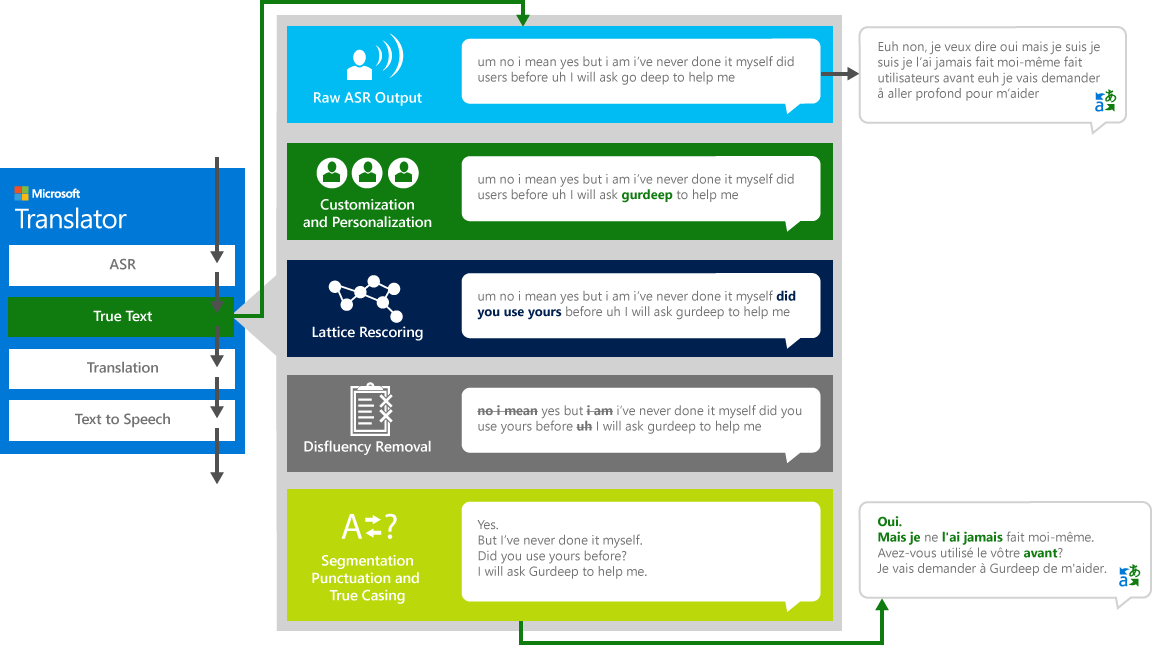
TrueText
Als mensen praten met andere mensen, spreken we niet zo perfect, duidelijk of netjes als we vaak denken dat we doen. Met de TrueText-technologie wordt de letterlijke tekst omgezet in een nauwer beeld van de gebruikers intentie door het verwijderen van spraak disfluencies (filler-woorden), zoals "um" s, "ah" s, "en" s, "like" s, stottert en herhalingen. De tekst wordt ook leesbaarder en vertaalbaar gemaakt door zin pauzes, goede interpunctie en kapitalisatie toe te voegen. Om deze resultaten te bereiken, gebruikten wij de decennia van het werk aangaande taaltechnologieën, ontwikkelden wij van vertaler om TrueText te creëren. Het volgende diagram toont, door middel van een real-life voorbeeld, de verschillende transformatie TrueText werkt om deze letterlijke tekst te normaliseren.
Vertaling
De tekst wordt vervolgens vertaald in een van de talen en dialecten ondersteund door Translator.
Vertalingen met behulp van de speech vertaling API (als een ontwikkelaar) of in een spraak vertaling app of dienst, wordt aangedreven met de nieuwste neurale-netwerk gebaseerde vertalingen voor alle spraak-invoer ondersteunde talen (Zie Hier voor de volledige lijst). Deze modellen werden ook gebouwd door het uitbreiden van de huidige, meestal geschreven tekst getrainde vertaling modellen, met meer gesproken-tekstcorpora om een beter model voorgesproken conversatie soorten vertalingen te bouwen. Deze modellen zijn ook verkrijgbaar via de "speech" standaardcategorie van de traditionele tekstvertaling API.
Voor alle talen niet ondersteund door neurale vertaling, is de traditionele SMT vertaling uitgevoerd.
Tekst naar spraak
Als de doeltaal een van de 18 ondersteunde tekst-naar-spraak- Talen, en de use-case vereist een audio-uitgang, wordt de tekst vervolgens omgezet in spraak-uitgang met behulp van spraaksynthese. Deze fase wordt weggelaten in spraak-naar-tekstvertaling scenario's.
Meer informatie over Microsoft's tekst naar spraakdiensten.
Onderzoek
Bekijk de meest recente research papers van het Microsoft Translator team.
- Universele neurale machine vertaling voor extreem lage resource talen
- Het bereiken van menselijke pariteit op automatische Chinees naar Engels Nieuws Vertaling
- Gender Aware GespRoken taal vertaling toegepast op Engels-Arabisch
- Synthetische gegevens voor neurale machine vertaling van GespRoken-dialecten



