At the Microsoft Research Montreal lab, one of our primary research focuses is to advance the field of Question Answering.
Automatic question-answering systems can provide humans with efficient access to vast amounts of information, and the task also acts as an important proxy for assessing machine literacy via reading comprehension.
Researchers in psychology have observed that humans improve their reading comprehension by asking questions about the material at hand. Inspired by this phenomenon, our latest effort in QA research involves teaching machines to jointly ask and answer questions.
To this end, we start with reformulating QA as a problem of conditional translation. That is, the goal of our QA model is to “translate” a document into an answer conditioned on the corresponding question. Analogously, question generation is achieved by translating based on a different condition (i.e., from document to question given the answer). Under this framework, knowledge could be transferred from question asking to question answering through the parameters shared between the two ”translation” models.
on-demand event

Microsoft Research Forum Episode 3
Dive into the importance of globally inclusive and equitable AI, updates on AutoGen and MatterGen, explore novel new use cases for AI, and more.
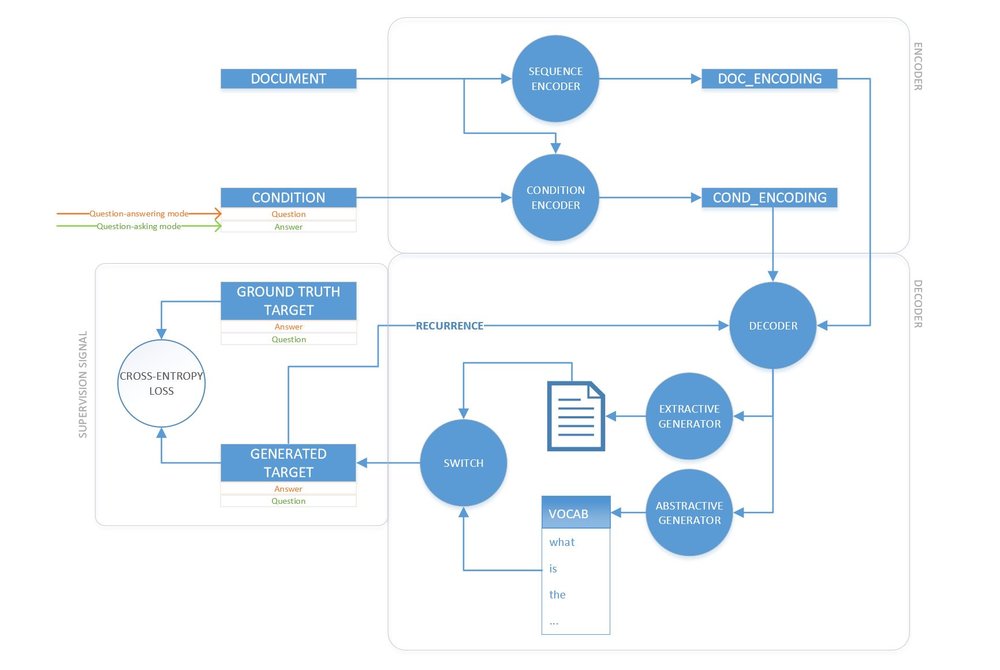
Figure 1: Model diagram
To test these ideas, we developed a sequence-to-sequence generative model (Figure 1) similar to our previously proposed question generator. One unique characteristic of the joint task is that during question-answering, the model’s output may be strictly extractive w.r.t. the document; that is, the answer is embodied in a span of text in the document that the model should simply extract or copy over. On the other hand, although a good question often contains important words from the document, it must also intersperse these with more general vocabulary and interrogative words. To properly model these observations, we opt for a special decoding architecture called pointer-softmax, which enables the model to learn to switch dynamically between (a) pointing to a word in the document and (b) decoding a word from a general vocabulary. This gives our decoder the unique capacity to generate abstractive answers (as opposed to the extractive boundary-pointing mechanism of most existing QA models, e.g., r-net). This ability should be useful in more open-ended settings, like online search.
We train our single model jointly by alternating mini-batches of question-answering and question-asking data. A QA-only baseline is established by training a model (with identical architecture) using QA-only data. When trained and tested on the SQuAD dataset, the joint model outperforms the QA-only baseline by close to 10 percentage points in F1 score, validating our hypothesis that question-answering can benefit from question-asking.

Table 1: A qualitative example demonstrating an attention shift possibly induced by the question-generation capacity in the joint model.
Our preliminary analysis suggests that knowledge transfer from question asking to question answering happens through “attention shift” in the document (though this conjecture must be verified). In Table 1, for example, the verb endorse has a rather complex object slot consisting of a direct object (his own vice president), an appositive (republican richard nixon), and an indirect object (democrat john f. kennedy). When the gold question asks about the direct object of the verb, the QA-only baseline makes a mistake by predicting the indirect object instead. After joint training, however, the model seems primed to focus its attention differently (here to ask about the appositive of the direct object in Q-mode), which helps the A-mode of the model sidestep the complexity of the objects and produce the correct answer. These examples are taken from the validation set and thus hidden from the model during training.
We believe that the proposed joint model offers a new perspective in advancing QA performance beyond architectural engineering approaches, and we hope that this contribution can also serve as a positive step towards autonomous information seeking.