

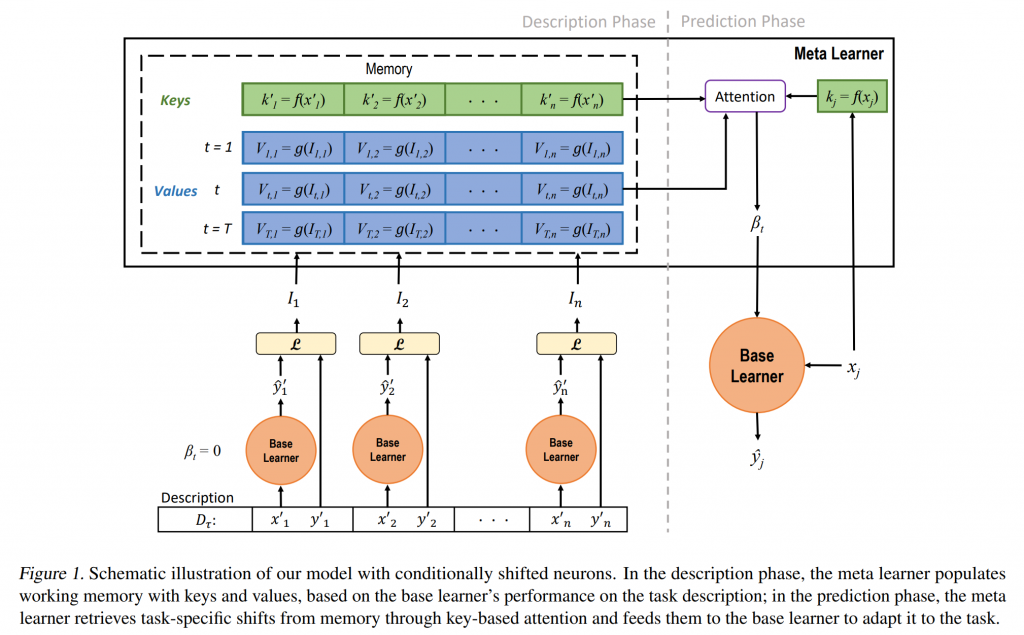
The Machine Comprehension team at MSR-Montreal recently developed a neural mechanism for metalearning that we call conditionally shifted neurons. Conditionally shifted neurons (CSNs) adapt their activation values rapidly to new data to help neural networks solve new tasks. They do this with task-specific, additive shifts retrieved from a key-value memory module populated from just a few examples.
Intuitively, the process is as follows: first, the model stores shift vectors that correspond to demonstrated class labels and keys them with corresponding input representations. Later, the model uses the representation it builds of an unseen input to query the memory for the stored label shift that corresponds to the most similar representation key. The additive conditional shifts can then activate or deactivate neurons on the fly, depending on the task and the contents of memory. From the optimization perspective, conditional shifting applies something like a one-step gradient update to the activations, rather than to the weights, of a network.
Spotlight: Event

Microsoft at CVPR 2024
Microsoft is a proud sponsor and active participant of CVPR 2024, which focuses on advancements in computer vision and pattern recognition.
As we demonstrate experimentally on three tasks, the CSN mechanism achieves state-of-the-art performance on few-shot classification problems. Read our paper (opens in new tab), just accepted to ICML 2018, for more detail.
Metalearning
Most machine learning systems excel at one single task and fall flat when tested on data outside their training distribution. They also tend to require gluts of data to master that single task. Contrast this with humans: we adapt our behavior on the fly, based on limited information, to tasks we’ve never seen before. The framework of metalearning (learning to learn) aims to replicate some of this flexibility in machines.
The goal of a metalearning algorithm is the ability to learn new tasks efficiently, given little training data from each individual task. One way to make this happen is to change the training setup: rather than showing a model how to do one big task with lots of data, we might show it a set of smaller, related tasks.
For example, instead of learning to recognize fifty breeds of dog (Dalmatians, Chihuahuas, Poodles, …) all at once, we could pose the more limited tasks of recognizing (a) Chihuahuas vs. Huskies, (b) Poodles vs. Bulldogs, and so on. There are general features of all dogs that remain (approximately) invariant across the smaller tasks — for instance, most dogs have four legs and a tail. A model can learn these invariances gradually, across tasks and over many examples, to help it ground and frame its perceptions. And then there are the specific, contrasting features of specific breeds that the model should pick up rapidly, from just a few examples for each individual task. For instance, it could pick up that the few images labeled “Dalmatian” all show spots, while the images labeled “Labrador” do not; ergo, spots are likely a unique feature of Dalmatians.
Ideally, a system trained in this way doesn’t learn to classify a fixed set of dogs; rather, it learns the meta procedure of how to rapidly discover discriminative features – the features that “split” the breeds. This means it could quickly determine how to classify any set of dogs, even if that set contains breeds it’s never seen before.
How CSNs Work
A CSN model factors into two parts: a base learner and a meta learner. The base learner is the neural network that makes predictions on data, whose neurons are modified by conditional shifts. The meta learner extracts information from the base learner, computes the conditional shift values, and stores them in its memory for later use by the base learner to adapt it to the task at hand.
As is standard in few-shot learning, our model operates in two phases: a description phase and a prediction phase. Assume that we have a distribution of related tasks from which we can sample, and that each task comes with a “description.” In the simplest case, the description is a set of example datapoints and their corresponding class labels.
In the description phase, the model processes the task description and attempts to classify its datapoints correctly. Based on its performance, which we can determine from the corresponding labels, it extracts conditioning information. The model uses this information to generate activation shifts to adapt itself to the described task and then stores these in a key-value memory module.
In the prediction phase, the model acts on unseen datapoints from the same task to predict their class labels. To improve these predictions, the model retrieves shifts from memory using a soft-attention mechanism and applies them to the activations of individual neurons.
We depict a model with CSNs in Figure 1. You can find a more detailed algorithmic description in our paper (opens in new tab).
One of the most appealing features of CSNs is their flexibility; the base learner can be any neural architecture — convolutional, recurrent, residual, etc. – and we can incorporate CSNs straightforwardly, without modifications to the different structures of these networks. This is also detailed in the paper.
Conditioning Information
The team evaluated two forms of conditioning information for rapidly adapting neural models. The first is the error gradient of the model’s classification loss on the task description. The model learns through training to map these gradients to conditional shifts. Adding these to the neuron activations in the prediction phase is like applying a one-step gradient update. Thus, instead of using gradient information to update the parameters of the model, which has an indirect effect on the output, we use the gradients to change the activation and output values directly. The meta learner uses its memory to record how these changes should be made.
Because backpropagation is sequential, the gradient conditioning information can be expensive to compute — especially for deeper networks, like RNNs processing long sequences. As an alternative, we propose the computationally cheaper direct feedback information, which achieves comparable results in less processing time (see the paper for details on what we mean by direct feedback).
Experiments and Results
The team evaluated CSNs on three few-shot classification benchmarks across the vision and language domains: Omniglot, Mini-ImageNet, and Penn Treebank (PTB).
A convolutional network with CSNs achieved results competitive with the state of the art on Omniglot 5- and 20-way classification. A ResNet with CSNs achieved state-of-the-art accuracy on Mini-ImageNet, reaching a new high of 71.94% mean accuracy on the 5-way, 5-shot setting. On the few-shot PTB language modelling task, we trained and tested LSTM networks augmented with CSNs in the recurrence. These models improved over the previous best by 11.1%, 16.0%, and 19.6% accuracy on the 5-way, 1-, 2-, and 3-shot tasks, respectively. For all benchmarks, direct feedback conditioning information performed comparably with the gradient-based information.
Experimental results indicate that conditionally shifted neurons are a powerful, generic mechanism for rapid adaptation of neural models in the metalearning setting.
Visualization of CSNs
We compared pre-softmax activations and their conditionally shifted variants to get a better idea of the inner working of CSNs. See Figure 2. We first trained a simple MLP on the Omniglot 1-shot 5-way classification task and then sampled and processed images from Omniglot’s test set. We recorded the pre-softmax activations before and after applying the task-specific shifts, then used t-SNE to project the vectors into a visualizable 2D space. The figure demonstrates that images with the same label are clustered more closely in the shifted activation space than the original space.
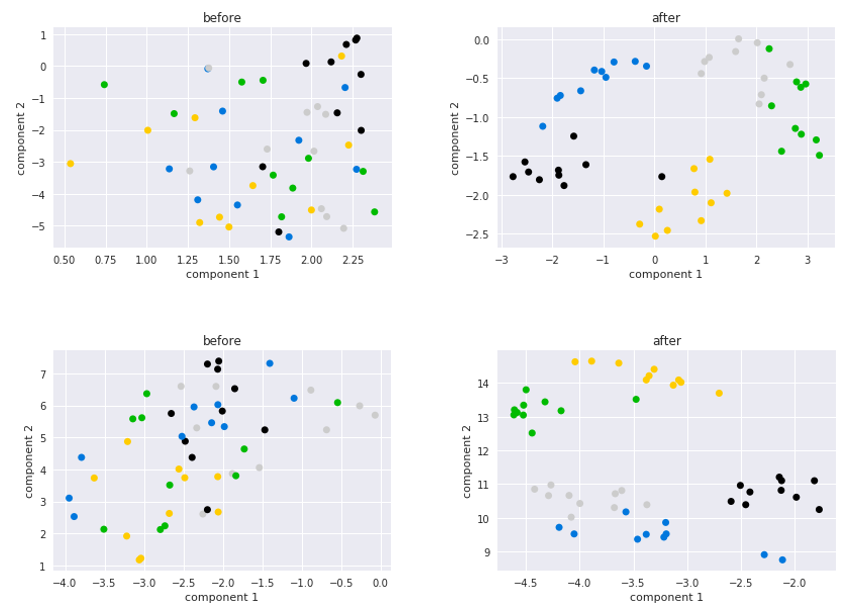

Figure 2. Each point represents an Omniglot image with a label indicated by its color. Pre-softmax activations are shown on the left and its shifted variants on the right sides.



