
I recently had the opportunity to attend two interesting conferences, NAACL (North America Association of Computational Linguistics) and CVPR (Computer Vision and Pattern Recognition). They are top conferences in the fields of natural language processing (NLP) and computer vision, respectively, and traditionally, their audiences are quite different. Along with all the exciting advances, I noticed an interesting coincidence: This year both conferences included a session on language and vision. However, perhaps this is not a coincidence. The merging of language and vision is one of the most active areas in NLP and computer vision research, and the community has made significant progress in this area over the past year, largely driven by recent breakthroughs in deep learning technologies and their applications in vision and language.
When I was at CVPR, I heard one question repeated several times: Why should vision researchers care about language processing? In computer vision, researchers recently built very deep convolutional neural networks (opens in new tab) (CNN), achieved an impressively low error rate in large-scale image classification tasks (opens in new tab), and even reached human-level image classification accuracy (opens in new tab) early this year. These accomplishments were achieved while requiring little understanding about language processing.
In order to teach a computer to predict the category of a given image, one way is for researchers to first annotate each image in a training set with a category label (called “supervision”) from a predefined list of 1000 categories. Through trial-and-error training, the computer learns how to classify an image.
Spotlight: Event
Inclusive Digital Maker Futures for Children via Physical Computing
This workshop will bring together researchers and educators to imagine a future of low-cost, widely available digital making for children, both within the STEAM classroom and beyond.
However, it’s a different situation when we want computers to understand complex scenes. In such cases, it is usually not possible to define simply by category all fine-grained, subtle differences among these scenes. Instead, the best supervision is full descriptions in natural language.

An example from the MS COCO dataset. (Microsoft Research)
Although the photos could be quite diverse, each description, annotated by a human, focuses on salient information in the image, delivers a coherent story with clear and consistent semantic meaning, and reflects certain common knowledge. These descriptions provide very rich information about the meaning of the picture, from a human point of view, and could serve as the supervision to train the computer to understand the image as a human does.
Another problem is how to test whether the computer understands the image. One way is to give the computer an image and ask the computer to generate a descriptive caption about it. We can discover how well the computer understands the image by looking at the generated caption through a Turing Test, in which we weigh the quality of the computer’s output against the output generated by humans for the same photograph.
For both of these training and evaluation problems, it is necessary for the computer to understand language. As a result, language processing is of particular importance for vision researchers for building strong artificial intelligence in vision.
In order to facilitate the research of image understanding, Microsoft sponsored the creation of the COCO (Common Objects in Context) dataset (opens in new tab), the largest image captioning dataset available to the public. The availability of the data was in part the motivation that led some groups from academic and industry institutes to work on solving the auto image captioning problem (opens in new tab) in the last year.
In order to have a rigorous comparison of different approaches and speed up the research for the community, the MS COCO committee (opens in new tab) organized an image captioning challenge (opens in new tab) at CVPR2015. There were a total of fifteen entries, and the top teams were invited to present their systems at the LSUN workshop (opens in new tab) at CVPR.
Microsoft tied Google (opens in new tab) for first prize at the competition. The MSR entry had slightly more outputs passing the Turing Test compared to the Google entry, though MSR generated slightly fewer captions that were better or equal to those generated by human annotators.
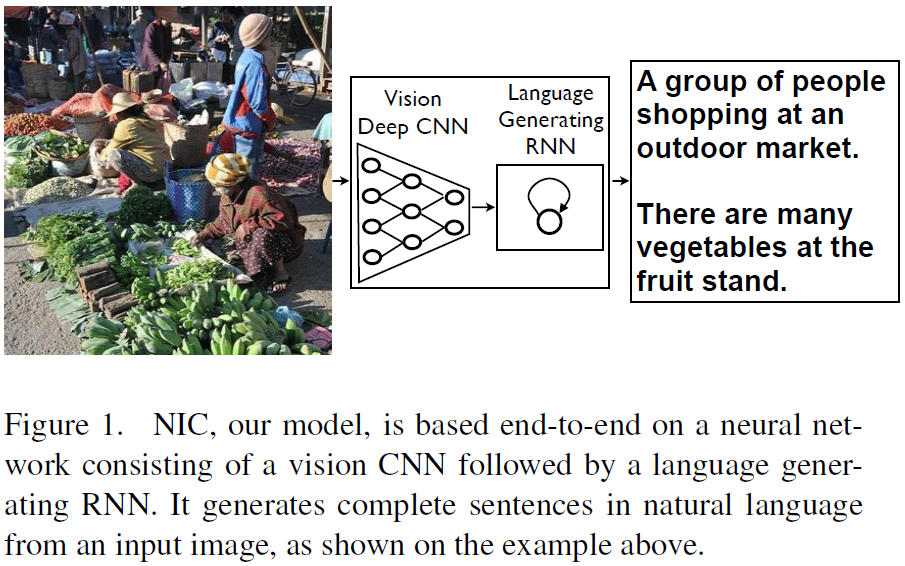
Google’s system uses a two-stage approach for direct caption generation. (Google)
Despite the tie, Microsoft and Google have quite different systems. Google uses a CNN to generate a whole-image feature vector, then feed it into a recurrent neural network (RNN) based language model to generate the caption directly.
In contrast, Microsoft’s system takes a three-stage approach. First, we tuned a CNN to detect multiple objects in the input image—not only nouns, but also verbs and adjectives (in this example, woman, crowd, cat, camera, holding, purple; note that this stage might introduce detection noise, such as cat).
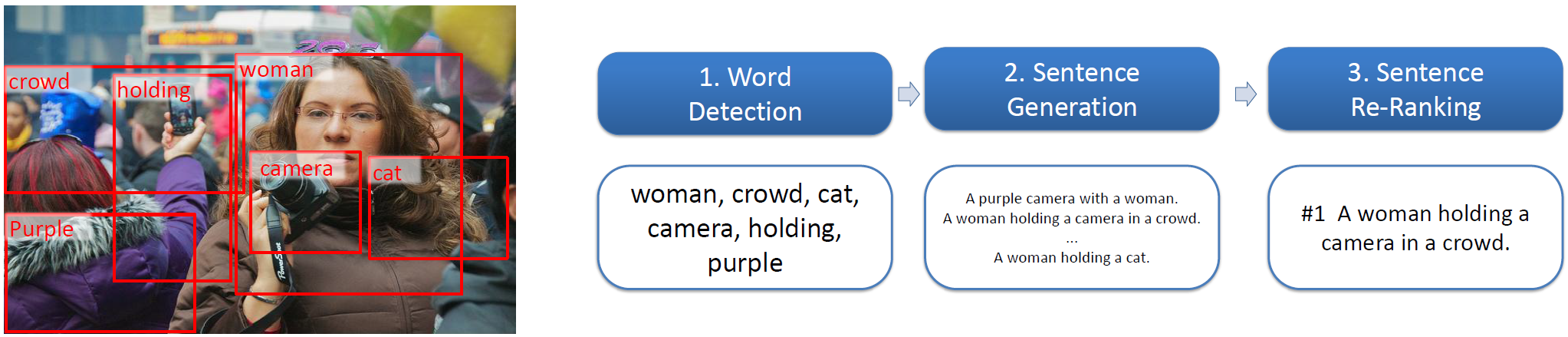 (opens in new tab)Microsoft’s system takes a three-stage approach. (Microsoft Research)
(opens in new tab)Microsoft’s system takes a three-stage approach. (Microsoft Research)
Second, we proposed an image-conditioned maximum entropy language model (LM) to generate 500 caption candidates that covered the detected words (a purple camera with a woman, a woman holding a camera in a crowd, a woman holding a cat.) The LM injects words such as a and with to make the caption read fluently.
Third, we developed a deep multimodal similarity model (DMSM) that re-ranks and selects the optimal caption that captures the overall semantic content of the image. (Note the noise in word detection and LM stages: the DMSM will pick the semantically correct caption a woman holding a camera in a crowd, and drop others that don’t match the global semantics of the image such as a purple camera with a woman and a woman holding a cat.)
Compared to the CNN->RNN approach Google and others adopted, our system can trace back and locate the region in the image for key words in the caption that the system generated, thanks to the explicit word detection. So it can provide grounded evidences for the generated caption and add interpretability to the outcome.
The results indicate that the current state-of-the-art system is about halfway to passing the whole Turing Test—that is, the MSR system scored 32.2% while a human scored 67.5%. (Note that even humans cannot pass with 100% since people disagree on the best way to describe an image. This also reflects the difficulty and ambiguity in the task of computer understanding of an image.)
Continuing in this line of investigation, researchers are already exploring advanced algorithms that translate videos to natural language (opens in new tab) and answer questions related to the content of an image (opens in new tab). In the future, by connecting speech, language, vision, and knowledge bases, we are looking forward to building a universal intellectual system that would blur the boundary between the machine and the human, with ubiquitous and invisible computational intelligence.

Xiaodong He is a researcher in the Deep Learning Technology Center (opens in new tab) of Microsoft Research (opens in new tab) in Redmond, Washington. He is also an Affiliate Professor (opens in new tab) in the Department of Electrical Engineering at the University of Washington (opens in new tab) (Seattle) serving in the PhD reading committee (opens in new tab). His research interests include deep learning, speech, natural language, vision, information retrieval, and knowledge management. He and his colleagues developed the MSR-NRC-SRI entry (opens in new tab) and the MSR entry (opens in new tab) which were No. 1 (opens in new tab)in the 2008 NIST MT Evaluation (opens in new tab) and the 2011 IWSLT Evaluation (opens in new tab), Chinese-English, respectively. He and colleagues also developed the MSR image captioning system (opens in new tab)that won the 1st Prize (opens in new tab) in the MS COCO Captioning Challenge 2015 (opens in new tab). He has published in Proc. IEEE, IEEE TASLP, IEEE SPM, ICASSP, ACL, EMNLP, NAACL, CVPR, SIGIR, WWW, CIKM, ICLR.
His current research focus is on deep learning for semantics and applications to text, vision, information retrieval, and knowledge graph (opens in new tab). Relevant studies are summarized in the recent tutorial at CIKM 2014 (opens in new tab). More details can be found at the DSSM site (opens in new tab).
He has held editorial positions on several IEEE Journals and has served on the organizing committee/program committee of major speech and language processing conferences. He is a senior member of IEEE and a member of ACL.
He received a BS degree from Tsinghua University (opens in new tab) (Beijing) in 1996, MS degree from Chinese Academy of Sciences (opens in new tab) (Beijing) in 1999, and a PhD degree from the University of Missouri, Columbia (opens in new tab), in 2003.
For more computer science research news, visit ResearchNews.com (opens in new tab).