Project Z-Code
Project Z-Code is a component of Microsoft’s larger XYZ-code initiative (opens in new tab) to combine AI models for text, vision, audio, and language. Z-code supports the creation of AI systems that can speak, see, hear, and understand. This effort is a part of Azure AI (opens in new tab) and Project Turing (opens in new tab), focusing on building multilingual, large-scale language models that support various production teams to evolve Microsoft products with the adoption of deep learning pre-trained models.
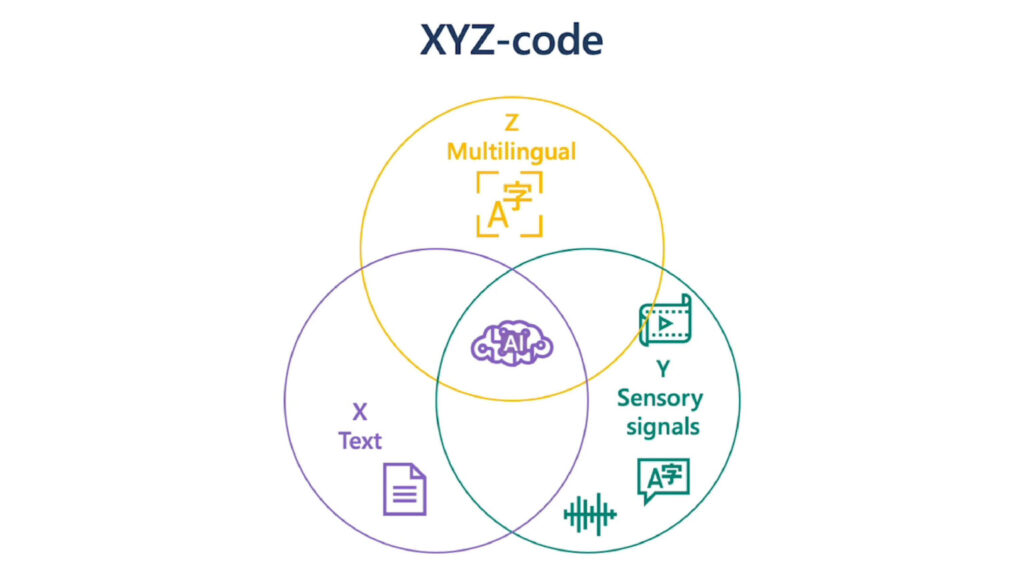
XYZ-Code combines three attributes of human cognition: monolingual text (X), audio or visual sensory signals (Y), and multilingual (Z) to create a joint representation enabling more powerful AI applications that can speak, hear, see, and understand humans better. We believe XYZ-code will enable us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. This can combine representation across languages and across modalities to drive cognitive services.
Z-Code, as a part of Project Turing (opens in new tab), realizing Micrsoft AI at Scale (opens in new tab) vision to empower Microsoft’s products and customers with large-scale multilingual pre-trained models to support a variety of applications. The project is focusing on various areas of the technology stack to scale AI models. We work on scaling up training infrastructure and frameworks such that we can enable training models with 100s billions of parameters on trillions of training examples in the most efficient and scalable setup. We work on fundamental modeling improvements that can enable cross-lingual and cross-domain transfer learning for hundreds of languages and various downstream tasks. Furthermore, we work on efficient runtime frameworks that enable cost efficient deployment of such large-scale models to serve various production scenarios in a more sustainable manner.

Z-Code, as the multilingual representation in XYZ-Code, is a general purpose pre-trained Multilingual, Multi-Task Text-to-Text Transformation model. In Z-code, we train the models on multiple tasks at the same time. Because of transfer learning, and sharing across similar languages, we have dramatically improved quality, reduced costs, and improved efficiency with less data. Now, we can use Z-code to improve translation and general natural language understanding tasks, such as multilingual named entity extraction. Z-code helped us deliver our embedded universal language regardless of what language people are speaking. As we like to say, Z-code is “born to be multilingual.”
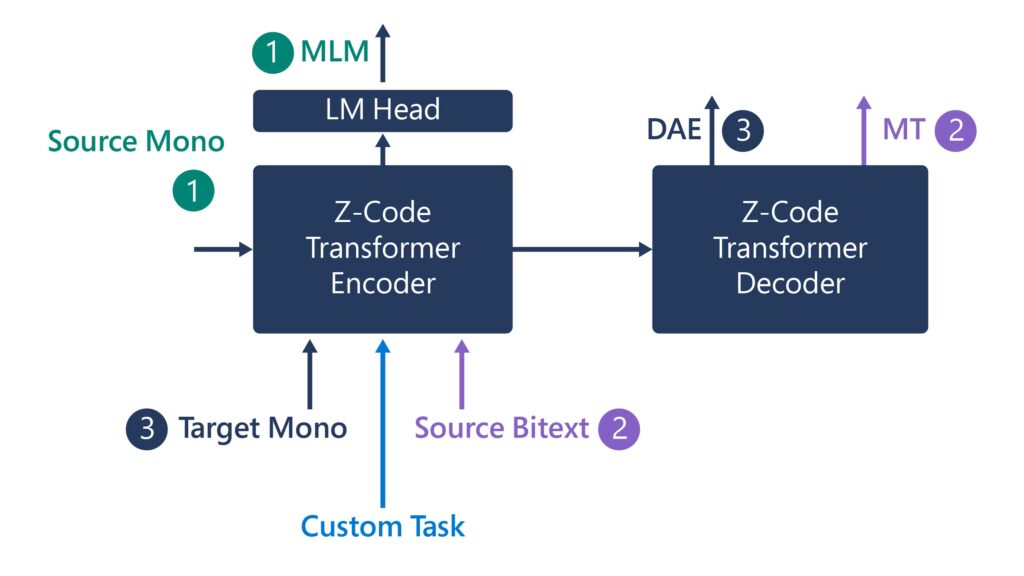
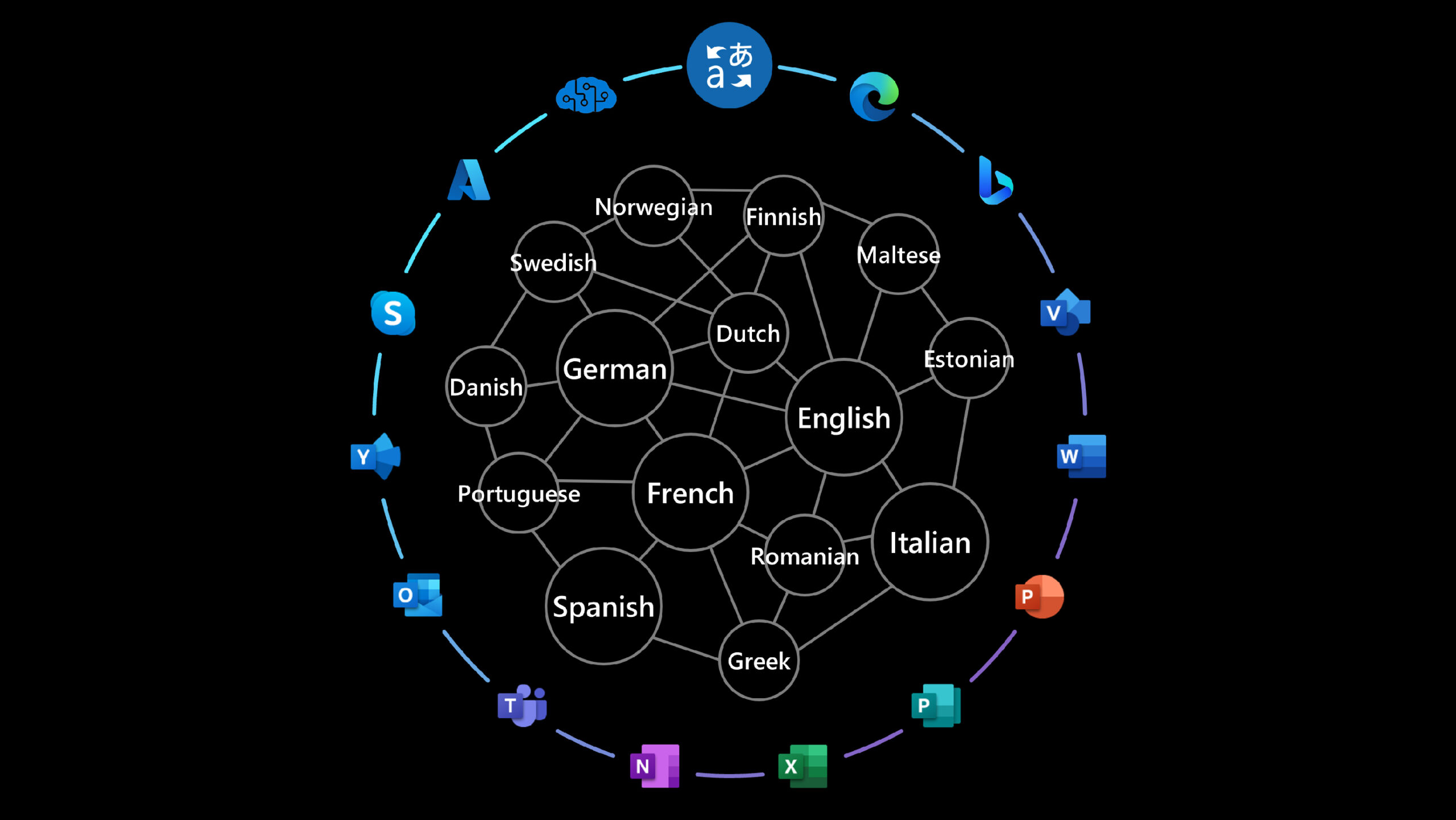
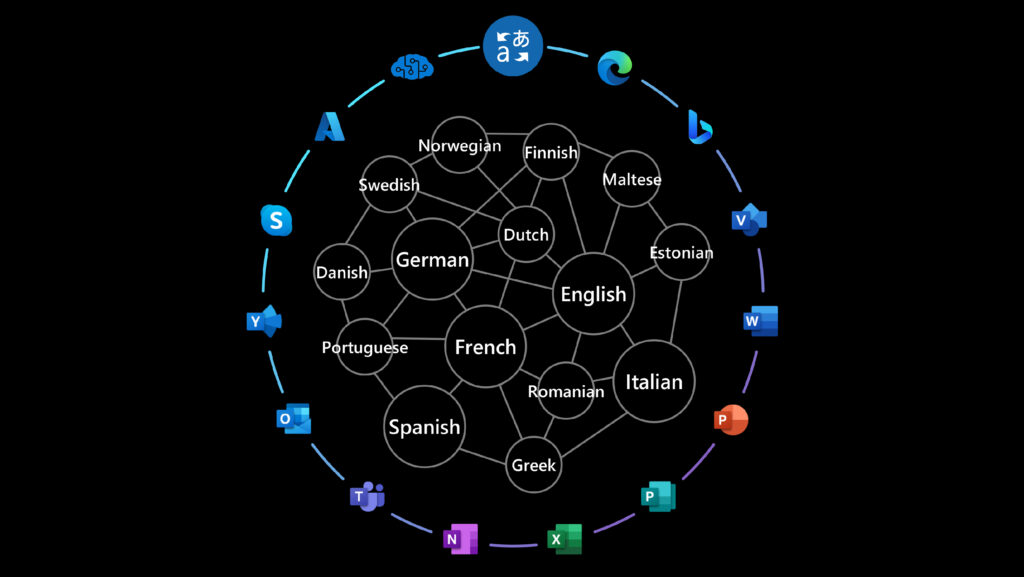
The model is trained on multiple tasks and multiple data sources to empower several production scenarios across Microsoft. Z-code takes advantage of shared linguistic elements across multiple languages via transfer learning —which applies knowledge from one task to another related task — to improve quality for machine translation and other language understanding tasks. It also helps extend those capabilities beyond the most common languages across the globe to underrepresented languages that have less available training data. Z-Code has a family of models covering both encoders only models and encoders-decoders generative models. The models empower various production scenarios across Microsoft with multilingual capabilities including Microsoft Translator, Azure Cognitive Services for Languages as well as several products scenarios in Teams, Office, and more.