
SpeechX
Neural Codec Language Model as a Versatile Speech Transformer
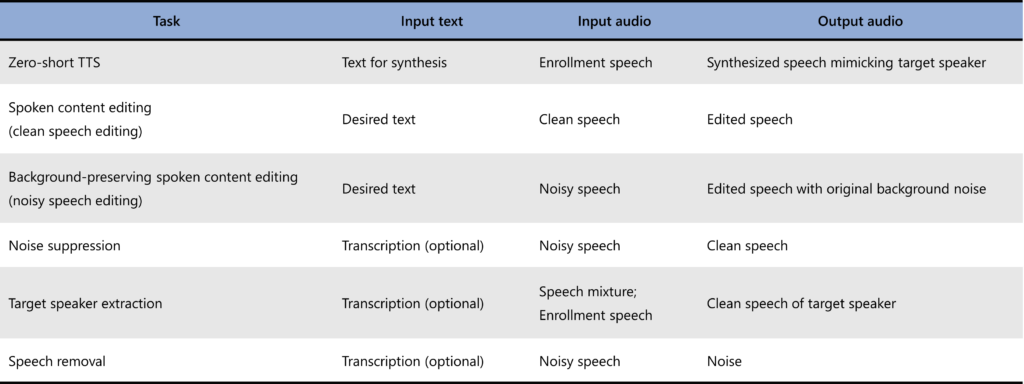
SpeechX is a versatile speech generation model leveraging audio and text prompts, which can deal with both clean and noisy speech inputs and perform zero-shot TTS and various tasks involving transforming the input speech. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting. This enables unified treatment of various tasks in an extensible manner, providing a consistent way of leveraging text input for speech enhancement and transformation. The current model, trained on 60K hours of speech audio, can perform zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing, where the spoken content can be altered while preserving the speaker and background sounds.
Model overview
SpeechX is a neural codec language model based on audio and text prompts and incorporates special tokens for task-dependent prompting, which helps the model to determine what a desired output is. The current model was trained on 60K hours of data from LibriLight.

Multiple tasks with one model
SpeechX deals with various input-output transformation relationships by employing a generic language modeling architecture using acoustic and textual tokens.
Applications / demo
Below, we included audio samples demonstrating how SpeechX performs in various speech-processing tasks. The audio files were normalized in amplitude and resampled at 16 kHz for listening. The speech samples and transcripts were taken from LibriSpeech test-clean. The speech samples below are provided for the sole purpose of illustrating SpeechX.
Zero-shot TTS (Text To Speech)
SpeechX synthesizes speech in the style specified by an audio prompt
| Text | Prompt (speaker) | SpeechX output | Ground truth |
|---|---|---|---|
| miss de graf said kenneth noticing the boy’s face critically as he stood where the light from the passage fell upon it | |||
| the paris plant like that at the crystal palace was a temporary exhibit | |||
| that summer’s emigration however being mainly from the free states greatly changed the relative strength of the two parties | |||
| it is my heart hung in the sky and no clouds ever float between the grave flowers and my heart on high |
Spoken content editing
SpeechX helps correct misspoken words.
| Original Text | Edited Text | Original speech | SpeechX output |
|---|---|---|---|
| cotton is a wonderful thing is it not boys she said rather primly | cotton is a wonderful thing with its soft and breathable texture she said rather primly | ||
| gold is the most common metal in the land of oz and is used for many purposes because it is soft and pliable | in the land of oz gold is the prevalent metal and is utilized for various reasons because it is soft and pliable. | ||
| its jaw is enormous and according to naturalists it is armed with no less than one hundred and eighty two teeth | its jaw is enormous and according to naturalists it is armed with no more than five hundred and thirty three teeth | ||
| shame on you citizens cried he i blush for my fellows of nottingham | citizens you should be ashamed cried he i blush for my fellows of nottingham |
Background-preserving spoken content editing
SpeechX naturally corrects misspoken words by preserving original ambience
| Original Text | Edited Text | Original speech | SpeechX output |
|---|---|---|---|
| we will go out together to the bower there is a way down to the court from my window | we will go out together to the bower there is a pathway down to the courtyard | ||
| she has been dead these twenty years | she has been dead thirty nine years | ||
| its origin was small a germ an insignificant seed hardly to be thought of as likely to arouse opposition | its origin was small a germ an insignificant seed always expected to provoke strong opposition | ||
| he was a fanatic on formality and he only addressed me in the third person to the point where it got tiresome | he was obsessive about protocol and always spoke to me in the third person to the point where it got tiresome |
Noise suppression
SpeechX removes unwanted background sounds that have been mixed into your recordings. Text input is optional, but it helps.
| Text | Noisy speech | SpeechX output | Ground truth |
|---|---|---|---|
| secure as he thought in the careful administration of justice in that city and the character of its well disposed inhabitants the good hidalgo was far from thinking that any disaster could befal his family | |||
| one day when the boy was sent by his grandfather with a message to a relation he passed along a street in which there was a great concourse of horsemen | |||
| the ideas also remain but they have become types in nature forms of men animals birds fishes | |||
| the salient features of this development of domestic service have already been indicated |
Target speaker extraction
SpeechX zeros in on one person in a mixture of voices
| Text | Prompt (speaker) | Mixed speech | SpeechX output | Ground truth |
|---|---|---|---|---|
| i allude to the goddess | ||||
| at that moment the gentleman entered bearing a huge object concealed by a piece of green felt | ||||
| I knew nothing of the doctrine of faith because we were taught sophistry instead of certainty and nobody understood spiritual boasting | ||||
| it is my heart hung in the sky and no clouds ever float between the grave flowers and my heart on high |
Speech removal
SpeechX can naturally erase human voices for audio redaction
| Noisy speech | SpeechX output | Ground truth |
|---|---|---|
Ethics statement
SpeechX could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While SpeechX can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.