
Ada-Ranker: A Data Distribution Adaptive Ranking Paradigm for Sequential Recommendation
- Xinyan Fan ,
- Jianxun Lian ,
- Wayne Xin Zhao ,
- Zheng Liu ,
- Chaozhuo Li ,
- Xing Xie
SIGIR 2022 |
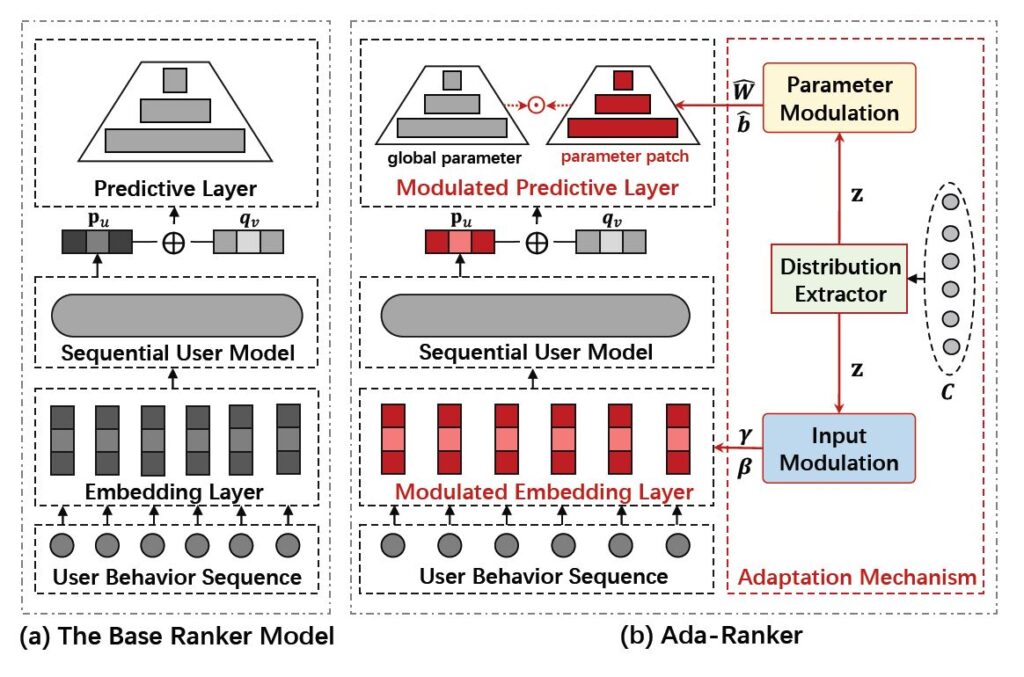
A large-scale recommender system usually consists of recall and ranking modules. The goal of ranking modules (aka rankers) is to elaborately discriminate users’ preference on item candidates proposed by recall modules. With the success of deep learning techniques in various domains, we have witnessed the mainstream rankers evolve from traditional models to deep neural models. However, the way that we design and use rankers remains unchanged: offline training the model, freezing the parameters, and deploying it for online serving. Actually, the candidate items are determined by specific user requests, in which underlying distributions (e.g., the proportion of items for different categories, the proportion of popular or new items) are highly different from one another in a production environment. The classical parameter-frozen inference manner cannot adapt to dynamic serving circumstances, making rankers’ performance compromised.
In this paper, we propose a new training and inference paradigm, termed as Ada-Ranker, to address the challenges of dynamic online serving. Instead of using parameter-frozen models for universal serving, Ada-Ranker can adaptively modulate parameters of a ranker according to the data distribution of the current group of item candidates. We first extract distribution patterns from the item candidates. Then, we modulate the ranker by the patterns to make the ranker adapt to the current data distribution. Finally, we use the revised ranker to score the candidate list. In this way, we empower the ranker with the capacity of adapting from a global model to a local model which better handles the current task. As a first study, we examine our Ada-Ranker paradigm in the sequential recommendation scenario. Experiments on three datasets demonstrate that Ada-Ranker can effectively enhance various base sequential models and also outperform a comprehensive set of competitive baselines.