
Brief Report: Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
- Yikeng Shen ,
- Shawn Tan ,
- Alessandro Sordoni ,
- Aaron Courville
ICLR 2019 |
ICLR 2019 Best Paper Award
Background:
Most linguists believe that language is hierarchically structured. Understanding and producing language would imply an acquired competence for nested tree structures governing how smaller constituents cluster to form larger structures of meaning. Although some evidence exists that current neural network models of language can implicitly elicit the hidden tree structures from its overt sequential form, the question remains of how to explicitly bias learning in these models to discover such structures, and whether the discovery of such structures could help in downstream tasks.
Setting:
Our model builds upon the well-established recurrent neural network language model using LSTM units. For each word in the input text, the LSTM produces a hidden state that is recursively updated and used to predict the next word in the sequence. Our method modifies the update of the hidden state and biases it towards estimating a statistic that can be used to infer a syntax tree via a simple top-down parsing algorithm detailed in the paper.
Methods:
The approach is based on the following intuition: whenever a constituent ends, its information is propagated to its parents in the syntax tree. This implies that the nodes near the root of the syntax tree contain information that slowly changes across time-steps in the sequence, while smaller constituents are more frequently updated. We propose to model this dynamic by “ordering’’ the hidden state neurons: high-ranking neurons will keep information over long time scales, while low ranking neurons are deemed to model rapidly changing information. At each time step, the model chooses which neurons need to be erased (updated). Crucially, all the neurons that follow them in the order will be erased (updated) too. This ensures the emergence of a hierarchy of information in the hidden states that is conducible to syntax trees. Particularly, we aim to encode the different nodes in the tree structure into different parts of hidden states. We propose to use a novel top-down parsing algorithm that takes as input the expected position of the neurons to erase in the hidden state and produces a binary tree as output. In our experiments, we show that the decisions about which neurons to update/erase learned by predicting the next word in the sequence are an accurate predictor of syntax structures labelled by expert linguists.
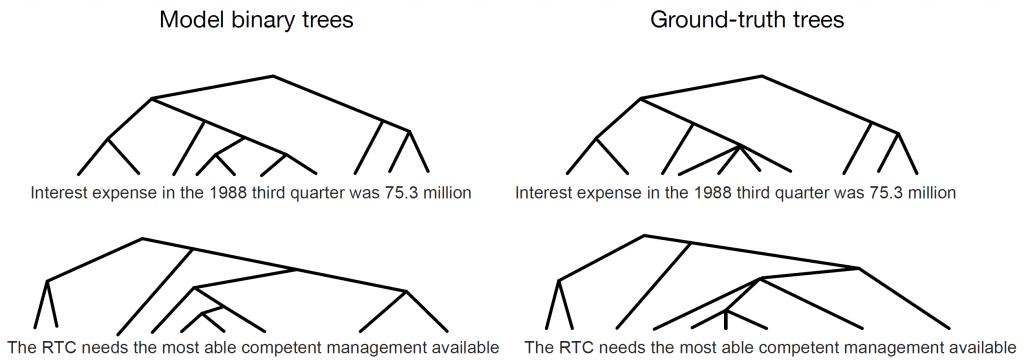
Results:
A quite interesting finding in our experiments is that our model achieves strong performance on unsupervised constituency parsing (49.4 UF1), that is, it can infer ground-truth unlabelled constituency syntax parse trees by training on a language modeling objective only. Better performance than comparable architectures is also reported on language modeling (56.12 ppl). Targeted syntactic evaluation highlights that our model can handle long-term syntactic agreement better than existing models, which may come as a result to its ability to internally build a model of syntax.
Conclusion:
The quest for conceiving better models of language is long-standing and still open. In this work, we provided a way to better align the internal functioning of recurrent neural network language models to the general principles at the core of language theories. We believe that being too interventionist by enforcing a particular a priori structure into the model would harm its performance: instead, we gently bias the model to favor the discovery of such structures. The empirical effectiveness on the unsupervised parsing task highlights that our model has the ability to discover, to a certain degree, the right structure. Thanks to this added competence, our model can achieve improved performance on language modeling, long-term syntactic agreement and logical inference tasks. We believe that future improvements in language modeling could be obtained by building models that are more effective at inferring an internal structured representation of language.