
Strojno prevajanje
Kaj je strojno prevajanje?
Sistemi za strojno prevajanje so aplikacije ali spletne storitve, ki uporabljajo tehnologije strojnega učenja za prevajanje velikih količin besedila iz in v kateri koli od njihovih podprtih jezikov. Storitev prevaja» izvorno «besedilo iz enega jezika v drug» ciljni «jezik.
Čeprav so koncepti za strojno prevajanje in vmesniki za njegovo uporabo razmeroma enostavni, so znanost in tehnologije, ki so v ozadju, izjemno zapleteni in združujejo več vrhunskih tehnologij, zlasti globokega učenja ( umetna inteligenca), velepodatki, Jezikoslovje, računalništvo v oblaku in spletni API-ji.
Od zgodnjih 2010s, nove umetne inteligence tehnologije, globoke nevronske mreže (aka globoko učenje), je omogočil tehnologijo prepoznavanja govora, da dosežejo raven kakovosti, ki je omogočila Microsoft Translator ekipa združiti prepoznavanje govora s svojo jedro besedila prevajanje tehnologije za začetek nove tehnologije prevajanja govora.
V preteklosti je bila tehnika primarnega strojnega učenja, ki se uporablja v industriji, statistična strojno prevajanje (SMT). SMT uporablja napredno statistično analizo, da oceni najboljše možne prevode za besedo glede na kontekst nekaj besed. SMT je bil uporabljen od sredine leta 2000s vseh večjih ponudnikov prevajalskih storitev, vključno z Microsoftom.
Pojav nevronske strojno prevajanje (NMT) povzročil radikalen premik v Prevajalski tehnologiji, zaradi česar je veliko višje kakovosti prevodov. Ta prevajalska tehnologija se je začela uvajat za uporabnike in razvijalce v zadnji del 2016.
Tako SMT in NMT prevajalske tehnologije imajo dva elementa skupnega:
- Oba zahtevata velike količine predčloveške prevedene vsebine (do milijone prevedenih stavkov) za usposabljanje sistemov.
- Ne delujejo kot dvojezični slovarji, prevajanje besed na podlagi seznama potencialnih prevodov, vendar prevesti na podlagi konteksta besede, ki se uporablja v stavku.
Kaj je prevajalec?
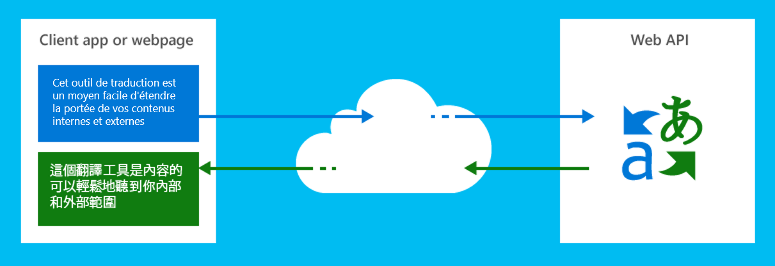
Prevajalsko in govorno službo, ki je del Kognitivne storitve zbirka API-jev, so storitve strojnega prevajanja od Microsofta.
Prevajanje besedil
Prevajalnik uporabljajo Microsoftove skupine od leta 2007, od leta 2011 pa je na voljo kot API za stranke. Prevajalec se v Microsoftu obsežno uporablja. Vključen je med lokalizacijo izdelkov, podporo in spletne komunikacijske ekipe. Ta ista storitev je dostopna tudi brez dodatnih stroškov znotraj znanih Microsoftovih izdelkov, kot so Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypein Yammer.
Prevajalec se lahko uporablja v spletnih ali odjemalskih aplikacijah na kateri koli strojni platformi in s katerim koli operacijskim sistemom za izvajanje prevajanja jezika in drugih jezikovnih postopkov, kot so zaznavanje jezika, besedilo v govor ali slovar.
Vplivna industrija standard REST tehnologija, razvijalec pošlje izvorno besedilo (ali audio za prevajanje govora) storitev s parametrom, ki označuje ciljni jezik, in storitev pošlje nazaj prevedeno besedilo za odjemalca ali spletne aplikacije za uporabo.
Storitev prevajalnika je storitev Azure, ki jo gosti Microsoftovi podatkovni centri, in koristi od razpoložljivosti varnosti, skalabilnosti, zanesljivosti in nonstop, ki jo prejmejo tudi druge Microsoftove storitve v oblaku.
Prevajanje govora
Prevajalska tehnologija prevajanja govora se je začela pozno 2014, začenša s storitvijo Skype Translator, od začetka leta 2016 pa je na voljo kot odprt API za stranke. Vključen je v funkcijo Microsoft Translator v živo, skype, oddajanje srečanj v Skypu in aplikacije Microsoft Translator za Android in iOS.
Prevajanje govora je zdaj na voljo prek Microsoftovega govora, nabora od konca do konca popolnoma prilagodljivih storitev za prepoznavanje govora, prevajanje govora in sinteze govora (besedilo v govor).
Kako deluje prevajanje besedila?
Obstajata dve glavni tehnologiji, ki se uporabljata za prevajanje besedila: zapuščina ena, statistični strojno prevajanje (SMT), in novejše generacije ena, nevronske strojno prevajanje (NMT).
Prevajanje statističnih strok
Prevajalska izvedba statističnega stroja (SMT) temelji na več kot desetletju raziskav v naravnem jeziku pri Microsoftu. Namesto pisanja ročno oblikovana pravila za prevajanje med jeziki, sodobni Prevajalski sistemi pristop prevajanje kot problem učenja preoblikovanje besedila med jeziki iz obstoječih človeških prevodov in vplivno nedavni napredek pri uporabi statistike in strojno učenje.
Tako imenovani "vzporedni corpora" deluje kot sodoben kamen Rosetta v množičnih razmerjih, ki zagotavlja besedo, frazo, in idiomatičen prevodi v kontekstu za številne jezikovne pare in domen. Tehnike statističnega modeliranja in učinkoviti algoritmi pomagajo računalniku obravnavati problem razbiranje (odkrivanje ustreznice med izvornim in ciljnim jezikom v podatkih o usposabljanju) in dekodiranje (iskanje najboljšega prevajanja novega vstopnega stavka). Prevajalec združuje moč statističnih metod z jezikovnimi informacijami za izdelavo modelov, ki posploševati boljše in vodijo k bolj razumljivemu prevodom.
Zaradi tega pristopa, ki se ne opira na slovarje ali slovnične predpise, zagotavlja najboljše prevode stavkov, kjer lahko uporabi kontekst okoli dane besede v primerjavi s poskušanju izvajanja enotne besede prevodov. Za prevajanje enojnih besed je bil razvit Dvojezični slovar in je dostopen prek www.Bing.com/Translator.
Prevajanje nevronskih strojev
Nenehne izboljšave prevajanja so pomembne. Vendar, predstava napredek življati stagniral s SMT Technology odkar srednji-2010s. Z vplivanjem obsega in moči Microsoft AI Supercomputer, posebej Microsoft Cognitive Toolkit, prevajalec zdaj ponuja nevronske mreže ((LSTM)) temelji na prevodu, ki omogoča novo desetletje izboljšanja kakovosti prevajanja.
Ti modeli nevronske mreže so na voljo za vse govorne jezike prek govora storitev na Azure in prek besedila API z uporabo "generalnn" kategorijo ID.
Nevronske mreže prevodi bistveno razlikujejo v tem, kako se izvajajo v primerjavi s tradicionalnimi SMT tiste.
Naslednja animacija prikazuje različne korake nevronske mreže prevodi gredo skozi prevesti stavek. Zaradi tega pristopa, prevod bo v kontekstu celoten stavek, v primerjavi le nekaj besed drsna okna, ki SMT tehnologija uporablja in bo proizvedla več tekočine in ljudi prevedenih videti prevodi.
Na podlagi usposabljanja nevronske mreže, vsaka beseda je kodirana vzdolž 500-dimenzije vektor (a), ki predstavlja svoje edinstvene značilnosti v določenem jeziku par (npr. angleščina in kitajščina). Na podlagi jezikovnih parov, ki se uporabljajo za usposabljanje, bo nevronska mreža sama opredelila, kaj bi morale biti te dimenzije. Lahko bi kodiranje preprostih konceptov, kot so spol (ženski, moški, nevtralni), vljudnost ravni (sleng, casual, pisno, formalno, itd), vrsta besede (glagol, samostalnik, itd), ampak tudi vse druge neočitne značilnosti, kot izhajajo iz podatkov o usposabljanju.
Koraki nevronske mreže prevodi gredo skozi so naslednje:
- Vsaka beseda, ali natančneje 500-razsežnost vektor, ki ga zastopa, gre skozi prvo plast "nevronov", ki bo kodiranje v 1000-razsežnost vektor (b), ki predstavlja besedo v okviru drugih besed v stavku.
- Ko so bile vse besede kodirane enkrat v teh 1000-razsežnost vektorji, postopek se ponovi večkrat, vsaka plast omogoča boljše fino tuning tega 1000-razsežnost zastopanje besede v okviru celotnega stavka (v nasprotju s SMT tehnologijo, ki lahko upošteva samo 3 do 5 besed okno)
- Končna izhodna matrika se nato uporablja plast pozornosti (tj. programski algoritem), ki bo uporabljal tako končno izhodno matriko kot tudi izhod prej prevedenih besed, da bi določili, katero besedo iz izvorne povedi je treba prevesti naprej. Te izračune bo uporabil tudi za morebitno zmanjšanje nepotrebnih besed v ciljnem jeziku.
- Dekoder (prevajanje) plast, prevaja izbrano besedo (ali natančneje 1000-razsežnost vektor, ki predstavlja to besedo v okviru celotnega stavka) v najustreznejši ciljni jezik enakovredni. Proizvodnja te zadnje plasti (c) se nato krmijo nazaj v plast pozornosti za izračun, ki naslednjo besedo iz izvorne stavka je treba prevesti.

V primeru, upodobljen v animaciji, kontekst-zaveda 1000-dimenzije model "na"bo kodiranje, da je samostalnik (House) je ženska beseda v francoščini (La Maison). To bo omogočilo ustrezen prevod za "na"biti"La"in ne"le"(ednina, moški) ali"Les"(množina), ko doseže dekoder (prevajanje) plast.
Algoritem za pozornost bo izračunal tudi na podlagi prej prevedenih besed (v tem primeru "na"), da mora biti naslednja beseda, ki jo je treba prevesti, predmet ("House") in ne pridevnik ("Modro"). V to lahko doseže, ker je sistem izvedel, da angleško in francosko invertni vrstni red teh besed v stavkih. Prav tako bi izračunal, da če bi bil pridevnik "Velik"namesto barve, da jih ne sme invertni njih ("Velika hiša"= >"La Grande Maison").
Zahvaljujoč temu pristopu, končni rezultat je, v večini primerov, bolj tekoče in bližje človeški prevod kot SMT temelji prevod bi lahko kdaj bil.
Kako deluje prevajanje govora?
Prevajalec je lahko tudi prevajanje govora. Ta tehnologija je izpostavljena v prevajalniku Live funkcijo (http://translate.it), prevajalec aplikacije, Skype Translator in je tudi sprva na voljo samo prek Skype Translator funkcijo in v aplikacijah Microsoft Translator na iOS in Android, ta funkcionalnost je zdaj na voljo razvijalcem z najnovejšo različico odprtega API, ki temeljijo na MIROVANJU, so na voljo na portalu Azure.
Čeprav se zdi, kot naravnost naprej proces na prvi pogled za izgradnjo tehnologije prevajanja govora iz obstoječe tehnologije opeke, je zahtevala veliko več dela, kot preprosto priklopom obstoječi "tradicionalni" človek-stroj za prepoznavanje govora motorja na obstoječi prevod besedila enega.
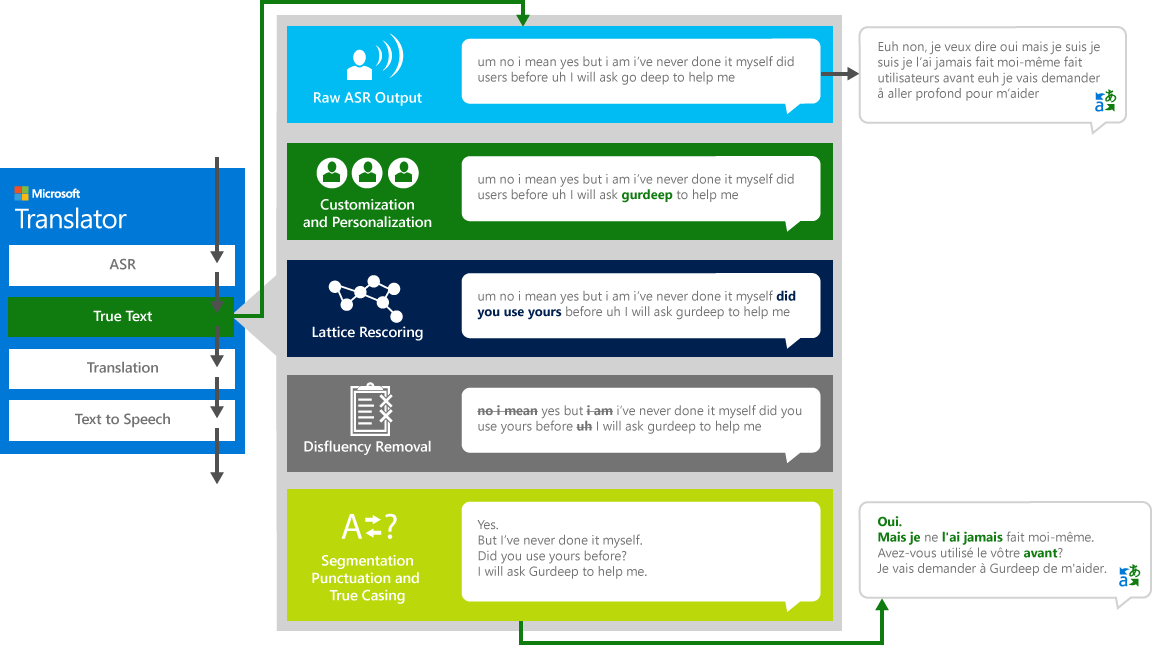
Če želite pravilno prevesti "vir" govor iz enega jezika v drug "ciljni" jezik, sistem gre skozi štiriletni proces.
- Prepoznavanje govora, pretvarjanje zvoka v besedilo
- TrueText: Microsoftova tehnologija, ki normalizira besedilo, da bi bila primernejša za prevajanje
- Prevajanje skozi mehanizem za prevajanje besedil, opisan zgoraj, vendar na modelih prevajanja, posebej razvitih za resnično življenje govornih pogovorov
- Besedilo v govor, če je potrebno, za izdelavo prevedenega zvoka.

Samodejno prepoznavanje govora (ASR)
Samodejno prepoznavanje govora (ASR) se izvaja z uporabo nevronske mreže (NN) sistem usposobljeni za analizo na tisoče ur dohodni zvočni govor. Ta model je usposobljen za interakcije med človekom in človekom in ne z ukazi človeka-stroj, ki proizvajajo prepoznavanje govora, ki je optimizirana za običajne pogovore. Da bi to dosegli, veliko več podatkov je potrebno, kot tudi večje DNN kot tradicionalni od človeka do stroja ASRs.
Preberite več o Microsoftov govor za besedilne storitve.
VeljaBesedilo
Kot ljudje conversing z drugimi ljudmi, ne govorimo kot popolnoma, jasno ali lepo, kot smo pogosto mislimo, da delamo. Z TrueText tehnologijo, se dobesedno besedilo pretvori v bolj natančno odražajo uporabnik nameri z odstranitvijo govora disfluencies (polnila besede), kot so "um" s, "ah" s, "in" s, "kot" s, jecljanje, in ponovitev. Besedilo je tudi bolj berljivo in prenosljiv z dodajanjem stavkov odmori, pravilno ločila, in kapitalizacija. Da bi dosegli te rezultate, smo uporabili desetletja dela na jezikovnih tehnologijah, smo razvili iz Translator ustvariti TrueText. Naslednji Diagram prikazuje, v realnem življenju primer, različne pretvorbe TrueText deluje za normalizacijo tega dobesednega besedila.
Prevod
Besedilo se nato prevede v katero koli jeziki in narečja podpira prevajalec.
Prevodi, ki uporabljajo API za prevajanje govora (kot razvijalec) ali v aplikaciji ali storitvi za prevajanje govora, se napaja iz najnovejšega nevronske mreže, ki temelji na prevodih, za vse jezike, ki podpirajo govor (glejte tukaj za celoten seznam). Ti modeli so bili zgrajeni tudi z razširitvijo sedanjega, večinoma pisno-Text usposobljenih modelov prevajanja, z več govorjenih-Text corpora zgraditi boljši model za govorjene vrste pogovorov prevodov. Ti modeli so na voljo tudi prek "govor" standardna Kategorija običajnega API-ja za prevajanje besedil.
Za vse jezike, ki jih Nevronski prevod ne podpira, se izvede tradicionalni SMT prevod.
Besedilo v govor
Če je ciljni jezik eden od 18 podprtih besedil v govor Jezikih, za primer uporabe pa je potreben zvočni izhod, se besedilo nato pretvori v izhodne podatke z uporabo sinteze govora. Ta faza je izpuščena v scenarijih prevajanja govora v besedilo.
Preberite več o Microsoftovo besedilo v govorne storitve.
Raziskave
Oglejte si najnovejše raziskovalne dokumente iz ekipe Microsoft Translator.



