
Машинний переклад
Що таке Машинний переклад?
Системи машинного перекладу – це застосунки або онлайнові служби, які використовують технології машинного навчання для перекладу великих обсягів тексту та на будь-яку з підтримуваних мов. Послуга переводить "Джерело" текст з однієї мови на іншу "цільову" мову.
Хоча поняття технології машинного перекладу і інтерфейсів для використання це відносно просто, наука і технології, за ним є надзвичайно складними і зібрати кілька передових технологій, зокрема, глибоке навчання ( штучний інтелект), великі дані, лінгвістика, хмарні обчислення, і веб-API.
З початку 2010 року, нові технології штучного інтелекту, глибокі нейронні мережі (ака Deep learning), дозволило технології розпізнавання мовлення досягти рівня якості, що дозволило команді Microsoft Перекладач поєднувати розпізнавання мовлення з його Основні технології перекладу тексту для запуску нової технології перекладу мови.
Історично, первинна методика навчання машин, що використовується в промисловості, була статистичною машинного перекладу (SMT). SMT використовує розширений статистичний аналіз для оцінки найкращого перекладу слів з урахуванням контексту кількох слів. SMT використовується з середини 2000-х років всіма основними постачальниками послуг перекладу, зокрема корпорацією Майкрософт.
Поява Нейромашинного перекладу (NMT) викликала радикальне зрушення в технології перекладу, в результаті чого значно вища якість перекладу. Ця технологія перекладу почала розгортанні для користувачів і розробників в Остання частина 2016.
І технології ЗПТ та NMT мають два спільні елементи:
- Обидва вимагають великої кількості попередньо людини перекладається зміст (до мільйонів перекладених пропозицій) для навчання систем.
- Не діють як двомовні словники, перекладаючи слова на основі списку можливих перекладів, але перекладаємо на основі контексту слова, що використовується в реченні.
Що таке Перекладач?
Послуги перекладача, мови, частини Пізнавальних послуг Колекція APIs, що є послугами машинного перекладу від корпорації Майкрософт.
Переклад тексту
Перекладач використовується групами Microsoft з 2007 року і доступний як API для клієнтів з 2011 року. Перекладач широко використовується в корпорації Майкрософт. Він включений у команди з локалізації продуктів, підтримки та онлайн-спілкування. Ця ж послуга також доступна без додаткових витрат зі знайомих продуктів Microsoft, таких як Бінг, Cortana, Microsoft EDGE, Office, Sharepoint, Skypeі Yammer.
Перекладач може бути використаний в Web або клієнтських додатках на будь-якій апаратній платформі і з будь-якою операційною системою для виконання мовного перекладу та інших операцій, пов'язаних з мовою, таких як визначення мови, текст в мову або словник.
Використання промисловості стандартні технології відпочинку, розробник посилає вихідний текст (або аудіо для перекладу мовлення) на службу з параметром, що вказує на цільову мову, і служба посилає перекладеного тексту для клієнта або веб-додатків для використання.
Служба перекладача — це служба Azure, яка розміщується в центрах обробки даних Microsoft і має переваги для забезпечення безпеки, масштабування, надійності та без зупинок, що також отримують інші хмарні служби Microsoft.
Переклад мови
Технологія перекладу мови перекладача була запущена в кінці 2014 року, починаючи з Skype Translator, і доступна як відкритий API для клієнтів з початку 2016 року. Він інтегрований в функцію Microsoft Translator, Skype, трансляцію нарад Skype і програми Перекладач Microsoft для Android та iOS.
Переклад мовлення тепер доступний за допомогою Microsoft мовлення, кінця-до-кінцевого набору повністю настроюваних служб для розпізнавання мовлення, перекладу мовлення та синтезу мовлення (Text-To-мовлення).
Як працює переклад тексту?
Існує дві основні технології перекладу тексту: спадщина, статистичний Машинний переклад (SMT), і новіший покоління, Нейромашинний переклад (NMT).
Статистичний Машинний переклад
Реалізація перекладацьких машинного перекладу (смт) побудована на більш ніж десятилітті дослідження природничо-мовних досліджень корпорації Майкрософт. Замість того, щоб писати створені вручну правила для перекладу між мовами, сучасні системи перекладу підхід перекладу, як проблема вивчення перетворення тексту між мовами з існуючих людських перекладів і використання останніх досягнень в застосуванні статистики та машинного навчання.
Так звані "паралельні корпора" виступають в якості сучасного Rosetta каменю в масивних пропорціях, надаючи слова, фрази і ідіоматичних перекладів в контексті багатьох мовних пар і доменів. Статистичні методи моделювання та ефективні алгоритми допомагають комп'ютеру вирішити проблему розв'язування (виявлення відповідності між вихідними та цільовими мовами в навчальних даних) та декодування (знаходження найкращого перекладу нового вхідного вироку). Перекладач об'єднує в собі силу статистичних методів з мовною інформацією для виробництва моделей, які узагальнювати краще і призводять до більш зрозумілих перекладів.
Через такий підхід, який не спирається на словники або граматичні правила, він надає кращі переклади фраз, де він може використовувати контекст навколо даного слова в порівнянні з спробою виконання одного перекладу слів. Для перекладу одного слова, двомовний словник був розроблений і доступний через www.Bing.com/Translator.
Нейромашинний Переклад
Важливі постійні удосконалення перекладу. Однак, покращення продуктивності мають plateaued з технологією ЗПТ з середини 2010s. Використовуючи масштаб і потужність комп'ютера штучного інтелекту від корпорації Майкрософт, зокрема, пізнавальний інструментарій Microsoft, Перекладач тепер пропонує нейронні мережі (LSTM) на основі перекладу, що дозволяє нове десятиліття поліпшення якості перекладу.
Ці нейронні мережеві моделі доступні для всіх мов мовлення через службу мовлення на Azure і через текстовий API за допомогою "генеренн" категорії ID.
Нейромережеві переклади принципово різняться в тому, як вони виконуються в порівнянні з традиційними ЗПТ Ones.
Наступна анімація зображує різні кроки нейромережевих перекладів пройти, щоб перевести вирок. У зв'язку з цим підхід, переклад буде приймати в контекст повне речення, в порівнянні лише кілька слів розсувних вікно, що SMT використовує технології і буде виробляти більше рідини і людини переведені переклади.
На основі нейромережі навчання, кожне слово закодовано по 500-Габаритні розміри вектора (a), що представляють свої унікальні характеристики в рамках конкретної мовної пари (наприклад, Англійська та Китайська). На підставі мовних пар, використовуваних для навчання, нейронні мережі самостійно визначити, що ці розміри повинні бути. Вони могли б кодувати прості поняття, такі як гендерні (жіночий, чоловічий, нейтральний), ввічливість рівня (сленгу, випадкові, письмові, формальні і т. д.), тип слова (дієслово, іменник і т. д.), але і будь-які інші неочевидні характеристики, отримані від підготовки даних.
Кроки нейромережевих перекладів проходять наступні дії:
- Кожне слово, або більш конкретно 500-вимір вектор представляють його, проходить через перший шар "нейронів", які будуть кодувати його в 1000-вимір вектор (b), що представляє слово в контексті інших слів у реченні.
- Як тільки всі слова були закодовані один раз в ці 1000-вимір векторів, процес повторюється кілька разів, кожен шар дозволяє краще тонкої настройки цього 1000-вимір представлення слова в контексті повного речення (всупереч ЗПТ технологія, яка може тільки брати до уваги 3 до 5 слів вікно)
- Остаточна вихідна матриця використовується шаром уваги (наприклад, алгоритм програмного забезпечення), який буде використовувати як остаточний матриці виводу і виведення раніше перекладених слів, щоб визначити, яке слово, від джерела речення, повинні бути переведені далі. Вона також буде використовувати ці розрахунки потенційно падіння непотрібних слів в цільовій мові.
- Декодер (переклад) шару, переводить вибране слово (або більш конкретно 1000-вимір вектор, що представляє це слово в контексті повного речення) в його найбільш підходящим еквівалент цільового мови. Вихід цього останнього шару (с) потім подається назад в шар уваги, щоб обчислити, яке наступне слово з джерела речення має бути переведений.

У прикладі, зображеного в анімаційній, контекстно-обізнаними 1000-розмірній моделі "на"буде кодувати, що іменник (Будинок) — жіночий слово французькою мовою (La Maison). Це дозволить відповідним перекладом на "на"бути"La"і не"Le"(Сингулярні, чоловіки) або"Les(Множинне) після того, як він досягне рівня декодера (Translation).
Алгоритм привернення уваги також буде обчислта на основі слова (-ів), попередньо перекладених (в даному випадку "на"), що наступне слово для перекладу повинно бути предметом ("Будинок"), а не прикметник ("Синій"). В може досягти цього, тому що система дізналася, що англійська та французька Інвертувати порядок цих слів в реченнях. Було б також підрахували, що якщо прикметник був бути "Великий"замість кольору, що він не повинен Інвертувати їх ("великий будинок"= >"La Grande Maison").
Завдяки цьому підходу, остаточний вихід, в більшості випадків, більш вільно і ближче до людини перекладу, ніж SMT основі перекладу міг би коли-небудь.
Як працює мова перекладу?
Перекладач також здатний перекладати мову. Ця технологія піддається функції перекладача Live (http://translate.it), Перекладач додатків, Skype Перекладач і також спочатку зробив доступним тільки через Skype функцію перекладача і в Microsoft Translator Apps на iOS і Android, Ця функціональність тепер доступна для розробників з останньою версією відкритого Доступний API для відпочинку на лазуровий порталі.
Хоча це може здатися прямим процесом вперед на перший погляд, щоб побудувати технологію перекладу мови від існуючої технології цегли, він вимагає набагато більше роботи, ніж просто підключити існуючий "традиційний" людина-машина розпізнавання мовлення двигун до існуючого тексту перекладу.
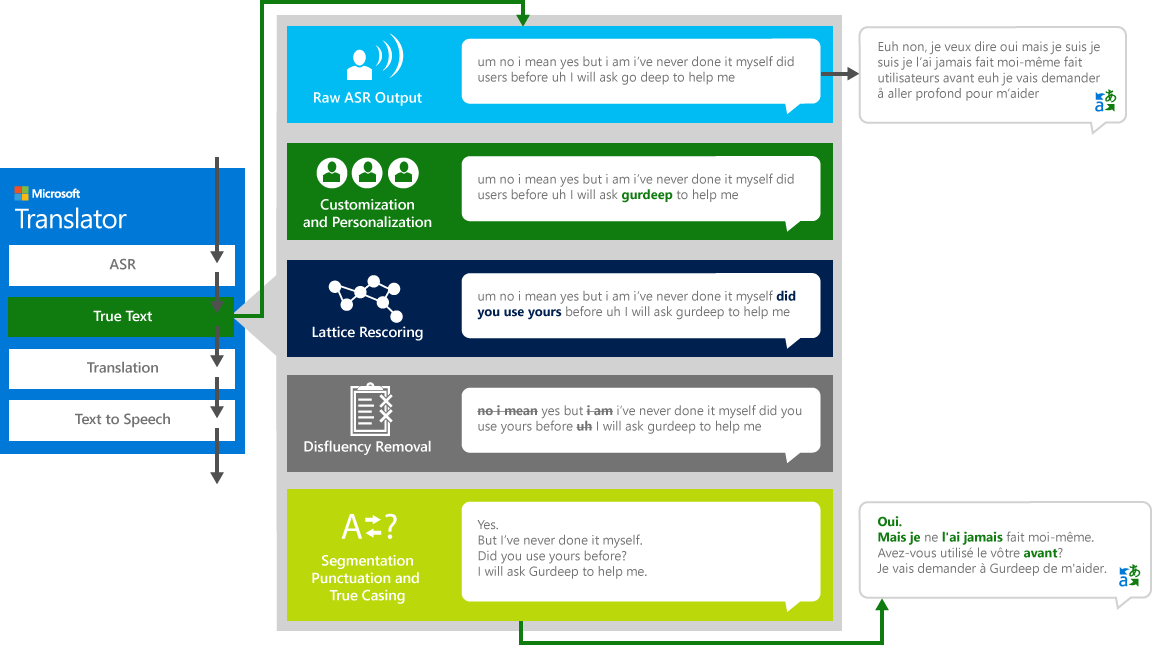
Для правильного перекладу "джерела" мови з однієї мови на іншу "цільову" мову, система проходить через чотири кроки процесу.
- Розпізнавання мовлення, перетворення звуку в текст
- TrueText: технологія Microsoft, яка нормалізує текст, щоб зробити його більш підходящим для перекладу
- Переклад за допомогою текстового двигуна, описаного вище, але на моделях перекладу, спеціально розроблених для справжнього життя розмовних розмов
- Text-To-Speech, коли це необхідно, для виробництва перекладеного звуку.

Автоматичне розпізнавання мовлення (ASR)
Автоматичне розпізнавання мовлення (ASR) виконується за допомогою системи нейронної мережі (NN), підготовлених за аналізом тисяч годин вхідного звукового мовлення. Ця модель навчається на людських взаємодія, а не від людини до машини команд, що виробляють розпізнавання мовлення, що оптимізовано для нормального спілкування. Для досягнення цього, набагато більше даних, необхідних, а також більше DNN, ніж традиційні людини до машини ASRs.
Дізнатися більше про Мовлення в текстових службах Microsoft.
TrueText
Як люди розмовляти з іншими людьми, ми не говоримо, як прекрасно, чітко або акуратно, як ми часто думаємо, що ми робимо. З технологією TrueText, буквальне текст перетворюється на більш тісно відображають наміри користувачів шляхом видалення disfluets мови (наповнювача слів), таких як "Um" s, "Ах" s, "і" s, "як" s, заїкається, і повторення. Текст також робиться більш читабельним та перекладним шляхом додавання розривів речень, правильного пунктуації та капіталізації. Для досягнення цих результатів ми використовували десятиліття роботи над мовними технологіями, ми розробили з перекладача для створення TrueText. Наступна діаграма зображує, через приклад реального життя, різні TrueText перетворення працює, щоб нормалізувати цей буквальний текст.
Переклад
Потім текст переводиться в будь-який з мови та діалекти підтримується перекладачем.
Переклади, які використовують API для перекладу (як розробник) або в застосунку або службі перекладу мовлення, живиться найновішими перекладами на основі нейромережних перекладів для всіх підтримуваних мов мови (див. Тут для повного списку). Ці моделі були також побудовані шляхом розширення поточного, в основному письмові-текст підготовлених моделей перекладу, з більш розмовним текстом, щоб побудувати кращу модель для розмовних типів розмов перекладів. Ці моделі також доступні через "мова" стандартна Категорія традиційних текстів перекладу API.
Для будь-яких мов, які не підтримуються нейроперекладом, проводиться традиційне перекладу SMT.
Текст на мовлення
Якщо цільова мова є однією з 18 підтримуваних синтезу мовлення Мови, а в разі використання потрібен аудіовихід, текст потім перетворюється на вивід мовлення за допомогою синтезу мовлення. Цей етап пропущено у сценаріях перекладу тексту за текстом.
Дізнатися більше про Текстові служби Microsoft для мовлення.
Дослідження
Перегляньте найновіші довідкові документи з команди перекладачів корпорації Майкрософт.



